
在前面提到了从0到1:学安全的你不该懂点AI?到上篇的最后提及了深度学习与机器学习的渊源——从1到无穷大—机器学习篇,这次我们就来聊聊深度学习在网络安全中应用。
首先需要强调一点,目前深度学习的定义并不一致,有的定义强调自动发现特征、有的强调复杂的非线性模型构造、有的强调从低层次到高层次的概念形成之类,因此本文不会对深度学习做出明确定义,只着眼于深度学习相关算法模型及其在网络安全领域的应用。
深度学习中“深度”是从算法层面讲的,源于神经网络,表示网络的层次是多层而不是早期的一层。在上篇文末有提到,深度学习这种计算是非线性的,可发现特征,可适应各种复杂的场景,深度学习厉害的地方也正是在于对原始数据进行多项与多层的运算。
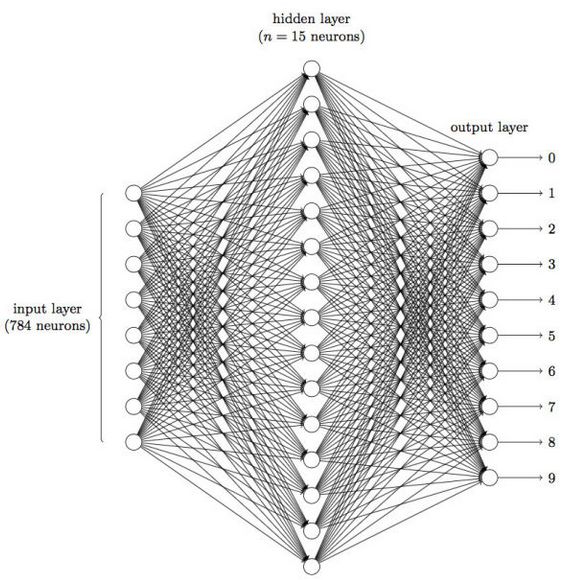
提到多层的神经网络,这儿顺便说一下CPU,GPU的关系
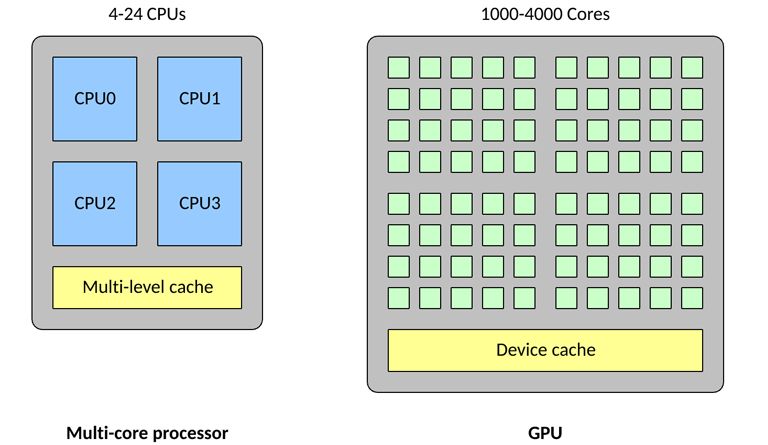
与传统CPU 相比,高密度的核心使得GPU 变得高度并行化,这使得GPU 成为大型神经网络的理想选择,在这些神经网络中,可以一次计算许多个神经元;另外GPU还擅长浮点矢量运算,因为神经元能执行的运算不止是矢量乘法和加法。所有这些特征使得GPU 上的神经网络达到所谓的高度并行。收益于此,使用高效率的深度学习成为可能。
深度学习的步骤还是这几步:数据的准备及预处理,训练模型,检测。最开始的数据的预处理及最后的检测在机器学习篇已经提到,不再重复,训练模型是最关键的,所以先来聊聊几个经典的模型。
RNN递归神经网络
带有一个指向自身的环,用来表示它可以传递当前时刻处理的信息给下一时刻使用,如下图所示,一条链状神经网络代表了一个递归神经网络,可以认为它是对相同神经网络的多重复制,每一时刻的神经网络会传递信息给下一时刻。
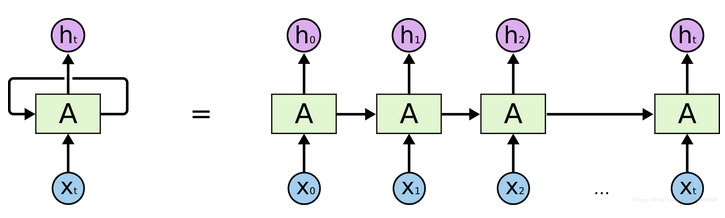
其中Xt为网络层的输入,A表示模型处理部分,ht为输出,A的细节实现如下图所示:
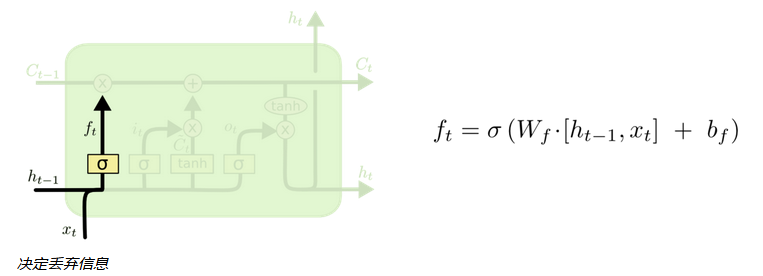
所有的递归神经网络都是由重复神经网络模块构成的一条链,处理层通常是一个tanh层,通过当前输入及上一时刻的输出来得到当前输出。它可以利用上一时刻学习到的信息进行当前时刻的学习了。每条线表示一个完整向量,从一个节点的输出到其他节点的输入。紫色圆圈代表逐点操作,比如向量加法,而黄色框表示的是已学习的神经网络层。线条合并表示串联,线条分叉表示内容复制并输入到不同地方。
递归神经网络因为具有一定的记忆功能,这种网络与序列和列表密切相关,可以被用来解决很多问题,例如:语音识别、语言模型、机器翻译等。在安全领域,利用网络态势预测即时间序列预测的特点可以用于预测网络安全态势(《基于RNN的网络安全态势预测方法》)等。
还是关键的四个步骤:
建议网络安全态势指标体系,从安全数据集中提取态势安全要素,并计算态势值;
依据态势指标体系建立RNN模型
输入训练样本集训练得到输出值并与知己态势值计算误差,反向更新模型参数,重复此过程直至误差小于期望误差
输入测试样本集,验证试验方案
LSTM长短期记忆网络
在聊完RNN之后,我们设想一种复杂的场景。假设我们试着去预测“Igrew up in France... I speak fluentFrench”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的France的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。在这个间隔不断增大时,RNN会丧失学习到连接如此远的信息的能力。此时,LSTM应运而生。
LSTM是一种RNN 特殊的类型,可以学习长期依赖信息。
LSTM区别于RNN的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为cell。
LSTM有能力对cell状态添加或者删除信息,这种能力通过一种叫门的结构来控制。一个cell当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入LSTM的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。
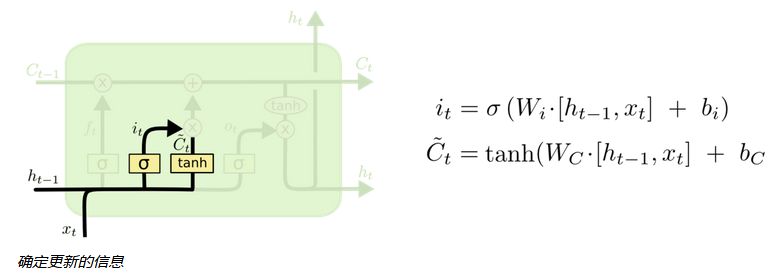
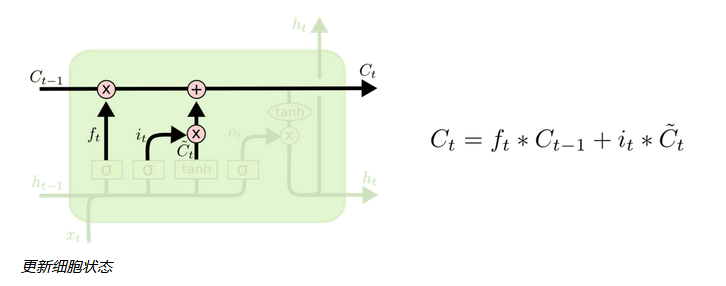
通过这一原理,可以在反复运算下解决神经网络中长期存在的大问题。目前已经证明,LSTM是解决长序依赖问题的有效技术,并且这种技术的普适性非常高,导致带来的可能性变化非常多,比如Yao,et al. (2015) 提出的Depth GatedRNN。还有用一些完全不同的观点来解决长期依赖的问题,如Koutnik,et al. (2014) 提出的ClockworkRNN。在安全领域,可使用CNN学习网络流量的下层空间特征,使用双向LSTM进一步学习网络流量的上层时序特征。上述特征学习过程由深层神经网络自动完成,无需任何特征工程技术,有效避免了手工设计特征带来的特征不准确等问题。同时,自动学习到的特征也有效地降低了误警率。(《基于深度学习的网络流量分类及异常检测方法研究》)
CNN卷积神经网络
卷积神经网络可能有数十个甚至数百个层,每个层学习检测图像的不同特征。卷积层滤波器会应用到不同分辨率的各个训练图像,且每个卷积图像的输出会用作下一层的输入。滤波器最初可以是非常简单的特征,例如亮度和边缘,然后增加复杂度,直至可以唯一地确定目标特征。像其他神经网络一样,CNN由一个输入层、一个输出层和中间的多个隐藏层组成。
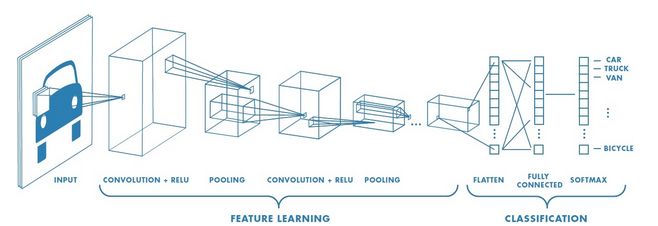
这些层执行可修改数据的操作,旨在学习特定于数据的特征。最常见的三个层是:卷积、ReLU 以及池化。
卷积:将输入图像放进一组卷积滤波器滤波器,每个滤波器滤波器激活图像中的某些特征。
ReLU层:通过将负值映射到零和保持正数值,实现更快、更高效的训练。有时候这称为激活,因为只有激活的特征才能转移到下一层。
池化:通过执行非线性下采样,减少网络需要学习的参数个数,从而简化输出。
这些操作在几十层甚至几百层上反复进行,每一层都学习识别不同的特征。
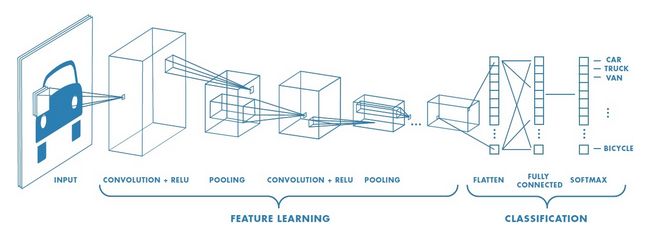
上图为具有大量卷积层的网络示例。滤波器会应用到不同分辨率的各个训练图像,且每个卷积图像的输出会用作下一层的输入。在学习完许多层中的特征之后,CNN的架构转移到分类。在上图可以看到倒数第二层是全连接层,输出K 维度的向量(K是网络能够预测的类数量)。此向量包含任何图像的每个类进行分类的概率。CNN架构的最后一层使用分类层(比如softmax)提供分类输出。
在安全领域,可以基于此进行网络流量分类。首先通过对数据进行归一化处理后映射成灰度图片作为卷积神经网络的输入数据,然后设计适于流量分类应用的卷积层特征面及全连接层的参数,构造能够实现流量的自主特征学习的最优分类模型,从而实现网络流量的分类。(《Classificationmethod of network traffic based on deep convolution neural network》)
DBN深度信念网络
是一门前沿技术,具有非线性的网络结构以及能够抽取数据的本质特征等优点,已在计算机视觉、语音识别、自然语言处理等领域取得瞩目的成果。
深度信念网络采用逐层训练的方式,解决了深层次神经网络的优化问题,通过逐层训练为整个网络赋予了较好的初始权值,使得网络只要经过微调就可以达到最优解。期间其最重要作用的就是受限玻尔兹曼机(RBM),限于篇幅,此处不详细展开。
简单地提一下:RBM,由可见层、隐层组成,显元用于接受输入,隐元用于提取特征。也就是说,通过RBM训练之后,可以得到输入数据的特征。另外,RBM还通过学习将数据表示成概率模型,一旦模型通过无监督学习被训练或收敛到一个稳定的状态,它还可以被用于生成新数据。
关于RBM,本质就是非监督学习的利器,可以用于降维、学习提取特征、自编码器以及深度信念网络(多个RBM堆叠而成)等等。
一个DBN模型由若干个RBM堆叠而成,训练过程逐层进行,如下图所示:
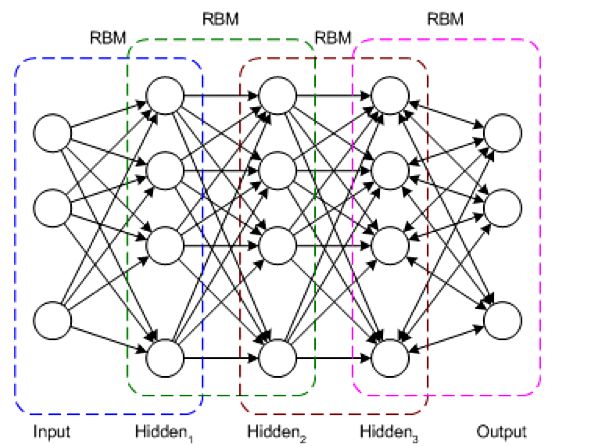
由于RBM的以上特点,使得DBN逐层进行训练变得有效,通过隐层提取特征使后面层次的训练数据更加有代表性,通过可生成新数据能解决样本量不足的问题。
实际场景中,常常将DBN的训练简化为对多个RBM的训练,从而简化问题。而且通过这种方式训练后,可以再通过传统的全局学习算法(如BP算法)对网络进行微调,从而使模型收敛到局部最优点,通过这种方式可高效训练出一个深层网络出来。
在安全领域,可以用于入侵检测算法的研究,利用多层的非线性结构进行特征提取,将高维的网络数据映射到低维空间,在特征提取过程中,抽取不同隐藏层的特征构成组合特征。最后将组合特征输入到随机森林中进行入侵检测识别。(《Researchon intrusion detection algorithm based on deep belief network》)
0x03
了解了几个典型的算法后,那么该如何应用呢?当然是用开源的框架啦。这部分就介绍几个比较流行的框架
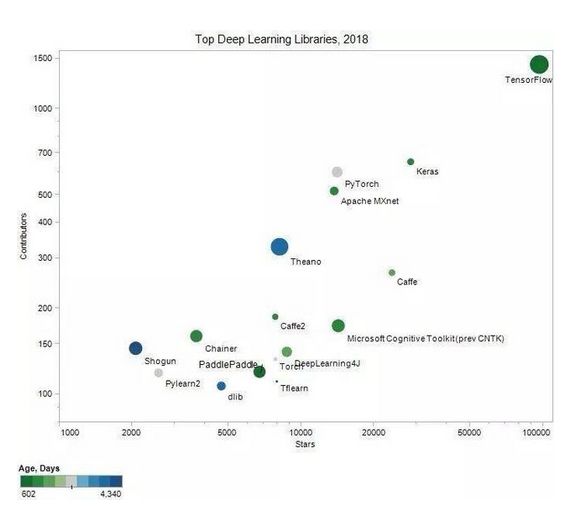
第一名当然是TensorFlow

TensorFlow最初由谷歌的MachineIntelligence research organization 中GoogleBrain Team的研究人员和工程师开发的。这个框架旨在方便研究人员对机器学习的研究,并简化从研究模型到实际生产的迁移的过程。
Keras

Keras是用Python编写的高级神经网络的API,能够和TensorFlow,CNTK或Theano配合使用
Caffe

Caffe是一个重在表达性、速度和模块化的深度学习框架,它由BerkeleyVision and Learning Center(伯克利视觉和学习中心)和社区贡献者共同开发。
这部分同样聊一聊深度学习的安全问题。
1.逃逸攻击(在机器学习篇已经稍微提及)
逃逸是指攻击者在不改变目标机器学习系统的情况下,通过构造特定输入样本以完成欺骗目标系统的攻击。例如,攻击者可以修改一个恶意软件样本的非关键特征,使得它被一个反病毒系统判定为良性样本,从而绕过检测。攻击者为实施逃逸攻击而特意构造的样本通常被称为对抗样本。只要一个机器学习模型没有完美地学到判别规则,攻击者就有可能构造对抗样本用以欺骗机器学习系统。
逃逸攻击主要有两种思路。一种思路是从对抗样本处着手,可分为白盒攻击和黑盒攻击,白盒攻击需要获取机器学习模型内部的所有信息,然后直接计算得到对抗样本;黑盒攻击则只需要知道模型的输入和输出,通过观察模型输出的变化来生成对抗样本。另一种思路是从软件漏洞着手,以手写图像识别为例,攻击者可以构造恶意的图片,使得人工智能系统在分类识别图片的过程中触发相应的安全漏洞,改变程序正常执行的控制流或数据流,使得人工智能系统输出攻击者指定的结果。思想还是传统软件攻防的思想,思路也分为两种:基于数据流篡改可以利用任意写内存漏洞,直接将AI系统中的一些关键数据进行修改(如标签、索引等),使得AI系统输出错误的结果;另一种则是通过常规的控制流劫持(如堆溢出、栈溢出等漏洞)来完成对抗攻击,由于控制流劫持漏洞可以通过漏洞实现任意代码的执行,因此必然可以控制AI系统输出攻击者预期的结果(《对深度学习的逃逸攻击— 探究人工智能系统中的安全盲区》)
针对逃逸攻击,方法之一是使用生成对抗网络(GAN)。GAN是一种深度学习技术,它使两个神经网络相互对抗以产生新数据。第一个网络即生成器创建输入数据,第二个网络,即分类器,评估由生成器创建的数据,并确定它是否可以作为特定类别传递。如果它没有通过测试,则生成器修改其数据并再次将其提交给分类器。两个神经网络重复该过程,直到生成器可以欺骗分类器认为它创建的数据是真实的。GAN可以帮助自动化查找和修补对抗性示例的过程
2. 恶意软件利用深度学习
IBM的研究人员引入了一种新的恶意软件,它利用神经网络的特性针对特定用户进行攻击,这类恶意软件可以根据他们的性别和种族,用特定深度学习算法来定位特定用户或群体。(更加具体的案例可以搜索“DeepLocker”)
3. 不可解释性
深度学习是一个“黑箱”学习方法。因为没有专业知识,只能盲目的黑箱式的学习,并且没法解释深度学习算法没有道德、常识和人类思维所具有的概念。它们的训练结果只反映了他们训练的数据。深度学习算法仅与其数据质量保持一致,因此为神经网络提供精心定制的训练数据的恶意行为者可能会导致其表现出有害行为。比如我们喂给模型数据的想表达的意思是用户下载数据量过多则判定为恶意行为,但是如果黑客以小增量增加他们的下载习惯来欺骗系统以慢慢地“训练”神经网络以认为这是他们的正常行为呢?
本文从深度学习基本概念出发,结合学术界部分论文讨论了深度学习中一些经典模型,之后结合github上的趋势简要介绍了最为流行的三个开源框架,在文末同样介绍了深度学习中的安全问题。
参考及推荐:
深度学习在安全领域应用研究的论文集合:
http://www.covert.io/deep-learning-security-papers/
吴恩达主讲课程
https://www.coursera.org/learn/machine-learning/home/info
吴恩达创办的一个公益性网站
Hinton(前文提到的深度信念网络的发明者)主讲课程
https://class.coursera.org/neuralnets-2012-001/lecture
递归神经网络深度剖析
理解LSTM网络
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
DL4J及深度学习指南
https://deeplearning4j.org/cn/quickstart

