
上一篇中已经提到了机器学习的相关概念,从0到1:学安全的你不该懂点AI?这一篇按照计划聊一聊机器学习与网络安全。
本系列主要以理论为主,觉得枯燥的话就去看兜哥的三部曲吧,网络安全结合我上篇提到的机器学习、深度学习和强化学习。个人建议还是应该沉下心先把理论打扎实,万丈高楼平地起,不把背后的原理搞清楚,只会调用这些库,终究会沦为调参民工的。

安全领域有四大顶级会议(CCS,S&P,USENIX,NDSS)近年来收录了50+的机器学习在网络安全中的研究,CSS会议甚至成立了专题AISec来研讨AI在安全领域的应用,另外在Defcon,BlackHat等黑客大会上关于机器学习与安全领域结合研究的议题也在逐年增加,当下,ML+Sec已经成为了关注热点,也是未来的趋势。
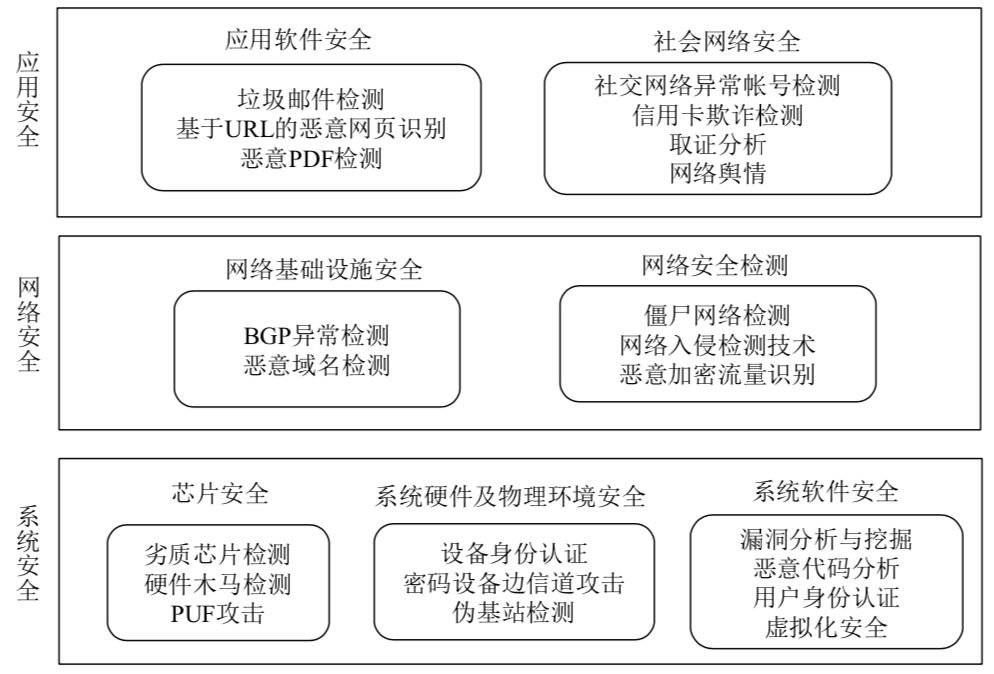
网络空间安全一级学科设立以来,主要有五个研究方向—网络空间安全基础,密码学及应用,系统安全,网络安全,应用安全,后三个研究方向颇受ML的青睐,大量的研究成果都是在这三个方向发表,工业界更是如此,现在几乎所有卖给甲方的安全产品都会套上“ml”的外衣。
这三个方向又可以细分为下图中的技术
我们知道机器学习一般有这么几个步骤:问题抽象-》数据采集-》数据预处理及安全特征提取-》模型构建-》模型验证-》效果评估,用机器学习的方法研究安全自然也不例外。
问题抽象
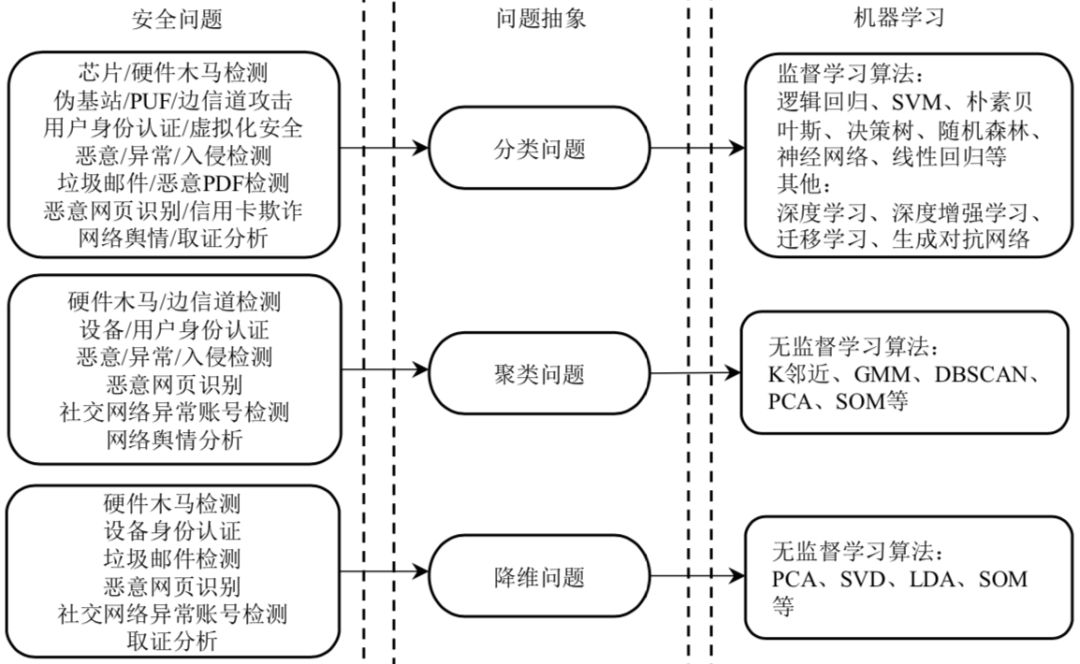
数据采集
企业有自身积累以及客户会提供部分数据,至于学术界一般会采用公开的数据集。一般有如下:
http://www.secrepo.com/安全相关数据样本集
http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.htmlKDDCup1999数据集
https://westpoint.edu/crc/SitePages/DataSets.aspx NSA的数据集
https://plg.uwaterloo.ca/~gvcormac/treccorpus07/ TREC公开垃圾邮件合集
http://www.sysnet.ucsd.edu/projects/url/恶意url数据集
https://github.com/foospidy/payloadsweb攻击payload数据集
https://www.ll.mit.edu/ideval/data/ DARPA入侵检测数据集等等
数据预处理及特征提取
这一部分的工作是相当重要的
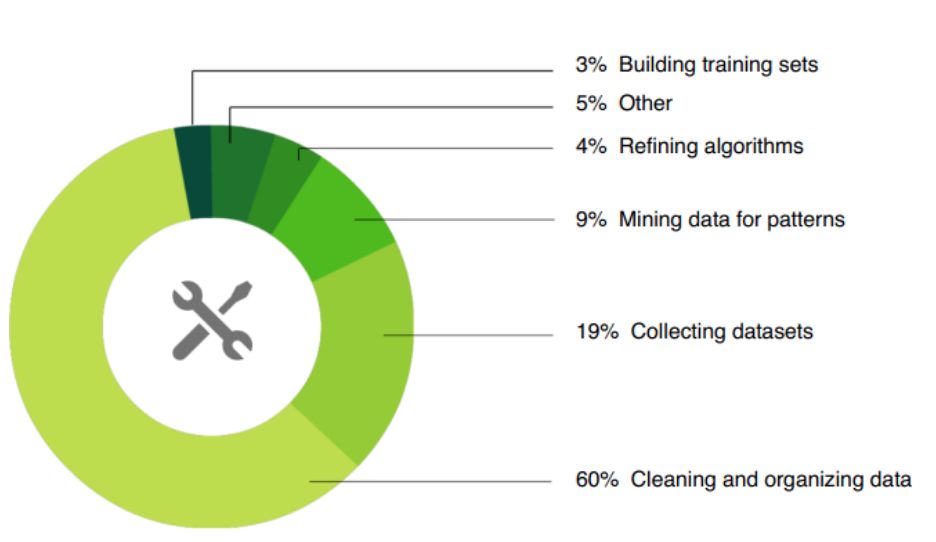
从上图就可以看出来60%的时间都是花在数据处理和提取上。
一般而言,必要的工作就是剔除重复数据,去噪等,然后进行聚类、归一化处理。期间会遇到很多问题,需要根据具体情况
比如缺失问题
首先看将要采用什么模型
如果是随机森林,贝叶斯网络等,这些模型它们自身能够处理数据缺失的情况,不需要我们做额外处理
如果不是采用那几个模型,此时要判断缺失情况
如果缺失较多,则舍弃,缺失较少,则填充,填充的方法又包括固定值填充、均值填充、中位数填充等。
非平衡问题
像入侵检测、恶意软件检测等方向攻击样本、恶意样本的数量远少于正常样本,此时直接套用模型自然会出问题,此时我们一般采用过采样或欠采样的方法进行平衡。
异常问题
首先要排除确实是数据异常,而不是人为失误,确实是数据的问题的话,一般作为缺失值处理。
处理之后需要进行分割,将其分为三个集合:训练集,验证集,测试集
接着就是特征提取,这一块基本上都是由专业的安全人员在做,比如提取payload,判断攻击行为等。实际上,这也是传统机器学习的主要缺陷之一--依赖于特征提取(featureextraction)——即人类专家规定每个问题的重要特征(比如属性)的过程。比如说为了实现机器学习能够识别恶意软件,安全人员需要首先手动编制与恶意软件相关的各种特征。对于网络安全领域而言,这无疑将会限制到威胁检测的效率和精确度。因为安全人员需要定义特定的特征,所以尚未定义到的特征可能就会逃避掉安全检测,使其无法被发现。此外,这种对人类参与的依赖还引发了机器学习最大的挑战之一——人为错误的可能性。鉴于特征工程需要人类专家来定义特征,就不可避免地会出现遗漏或忽略等人为失误现象。还是以恶意软件为例,如果人类专家在编程期间遗漏或忽略某些特征,都可能会造成系统崩溃的结果。
模型构建
模型构建包括算法选择和参数调优两个部分
算法的话就如上篇提到的,分为无监督学习和有监督学习。
监督学习典型算法包括
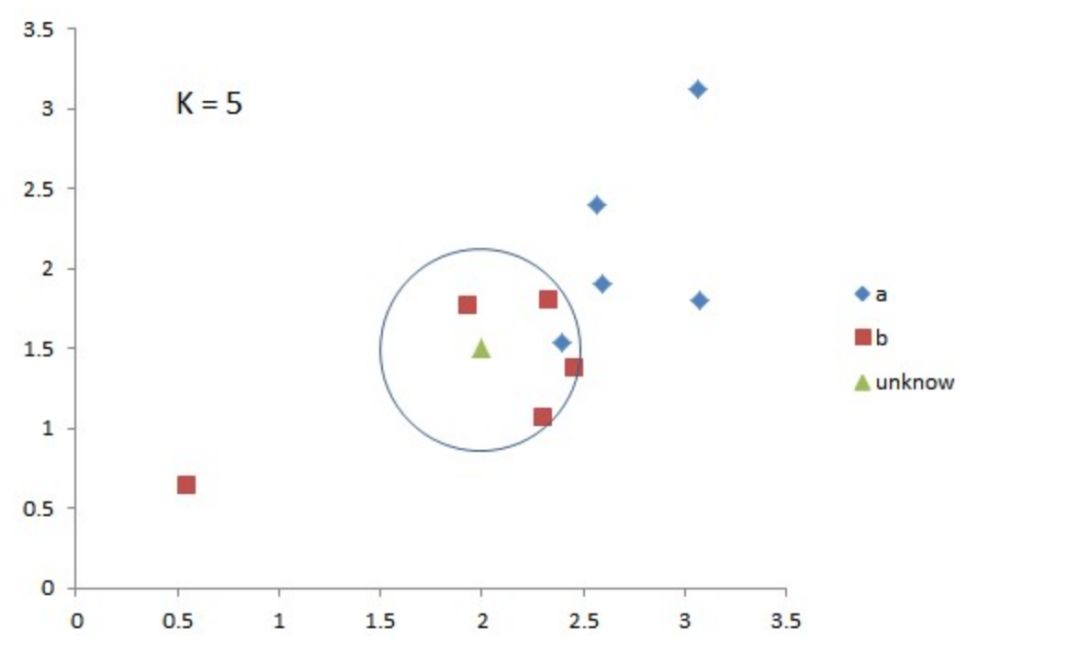
K-近邻算法
核心思想是由K确定“近邻”的范围,由近邻的数值和属性得出特定未知变量的数值和属性。俗话说的“人以类聚”就是这个算法的体现。
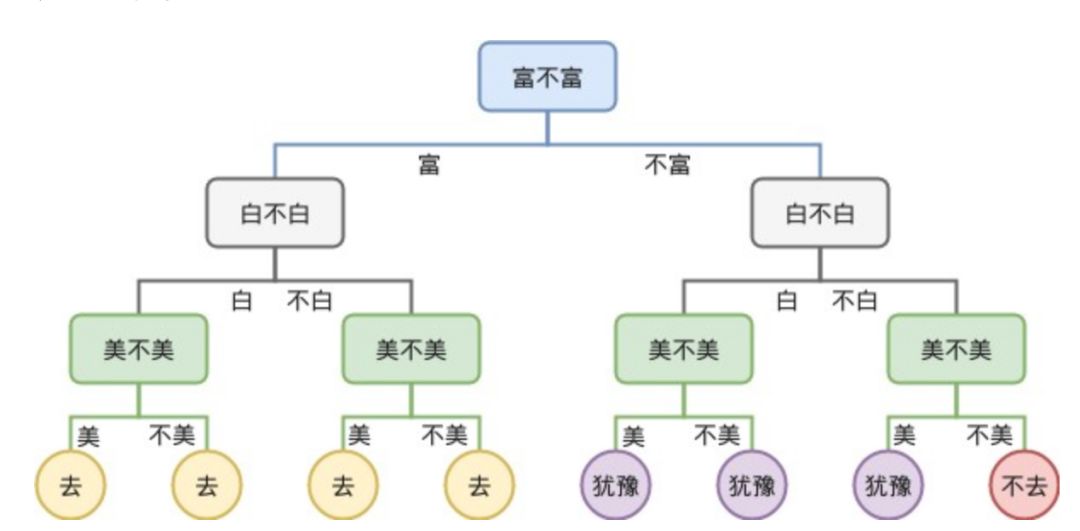
决策树
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。下图是一个二叉树的示例
朴素贝叶斯
朴素,英文原文是naïve,意思是表示所有特征变量间相互独立,不会影响彼此。主要思想就是:如果有一个需要分类的数据,它有一些特征,我们看看这些特征最多地出现在哪些类别中,哪个类别相应特征出现得最多,就把它放到哪个类别里.比如我们要判断一个人物,有如下特征1)超级英雄2)有盾牌3)美国人4)和钢铁侠打过架,结合这四个特征,才能得出这个人物是美国队长,单靠某一个特征是无法得出的。

无监督学习典型算法包括
K-Means(K均值算法)
1.随机的选取K个中心点,代表K个类别;
2.计算N个样本点和K个中心点之间的欧氏距离;
3.将每个样本点划分到最近的(欧氏距离最小的)中心点类别中——迭代1;
4.计算每个类别中样本点的均值,得到K个均值,将K个均值作为新的中心点——迭代2;
5.重复234;
6.得到收敛后的K个中心点(中心点不再变化)——迭代4。

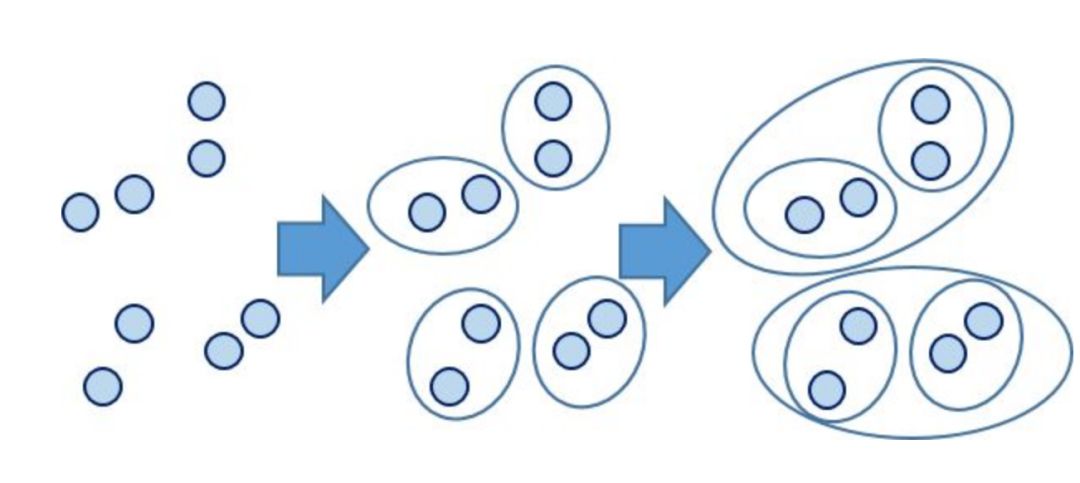
层次聚类算法
将每个样本都视为一个聚类
计算各个聚类之间的相似度
寻找最近的两个聚类,将他们归为一类
重复2,3
直到所有样本归为一类。
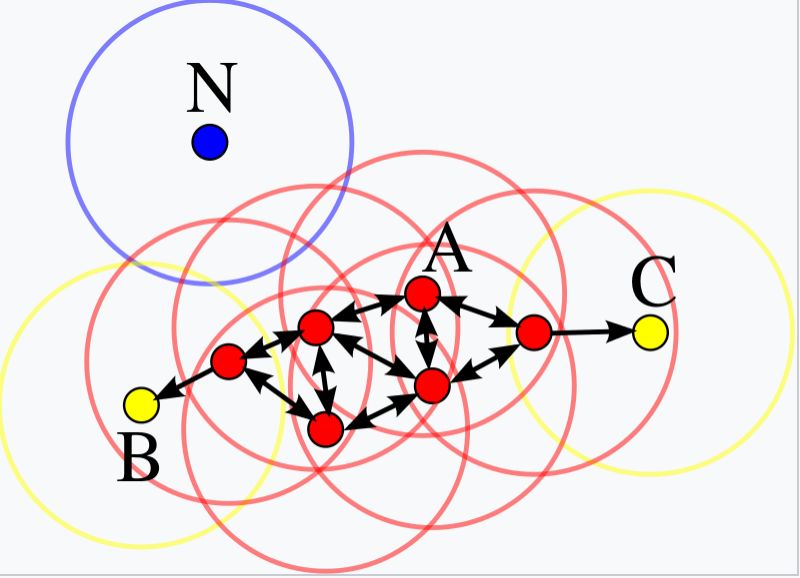
DBSCAN密度聚类算法
给定某空间里的一个点集合,这算法能把附近的点分成一组(有很多相邻点的点),并标记出位于低密度区域的局外点(最接近它的点也十分远)
下图中,minPts= 4,点 A和其他红色点是核心点,因为它们的ε-邻域(图中红色圆圈)里包含最少4 个点(包括自己),由于它们之间相互相可达,它们形成了一个聚类。点B 和点 C不是核心点,但它们可由 A经其他核心点可达,所以也属于同一个聚类。点N 是局外点,它既不是核心点,又不由其他点可达。
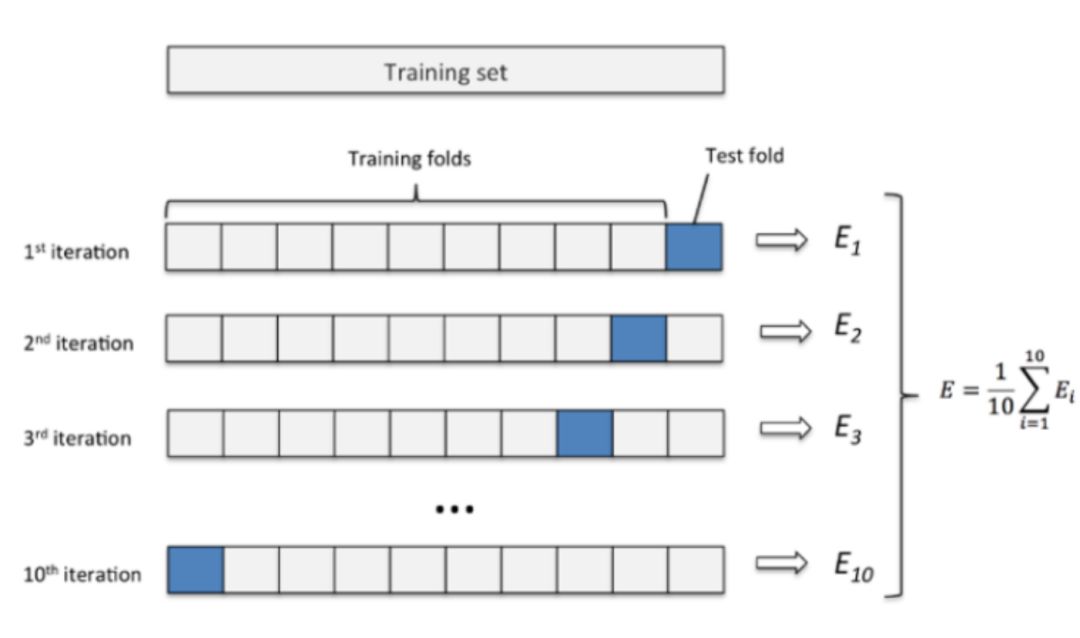
模型验证
最常用的就是k折交叉验证法。K次交叉验证,将训练集分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10次交叉验证是最常用的,称作10倍交叉验证模型。
效果评估
安全领域分类问题效果评估指标

机器学习在系统安全中的应用
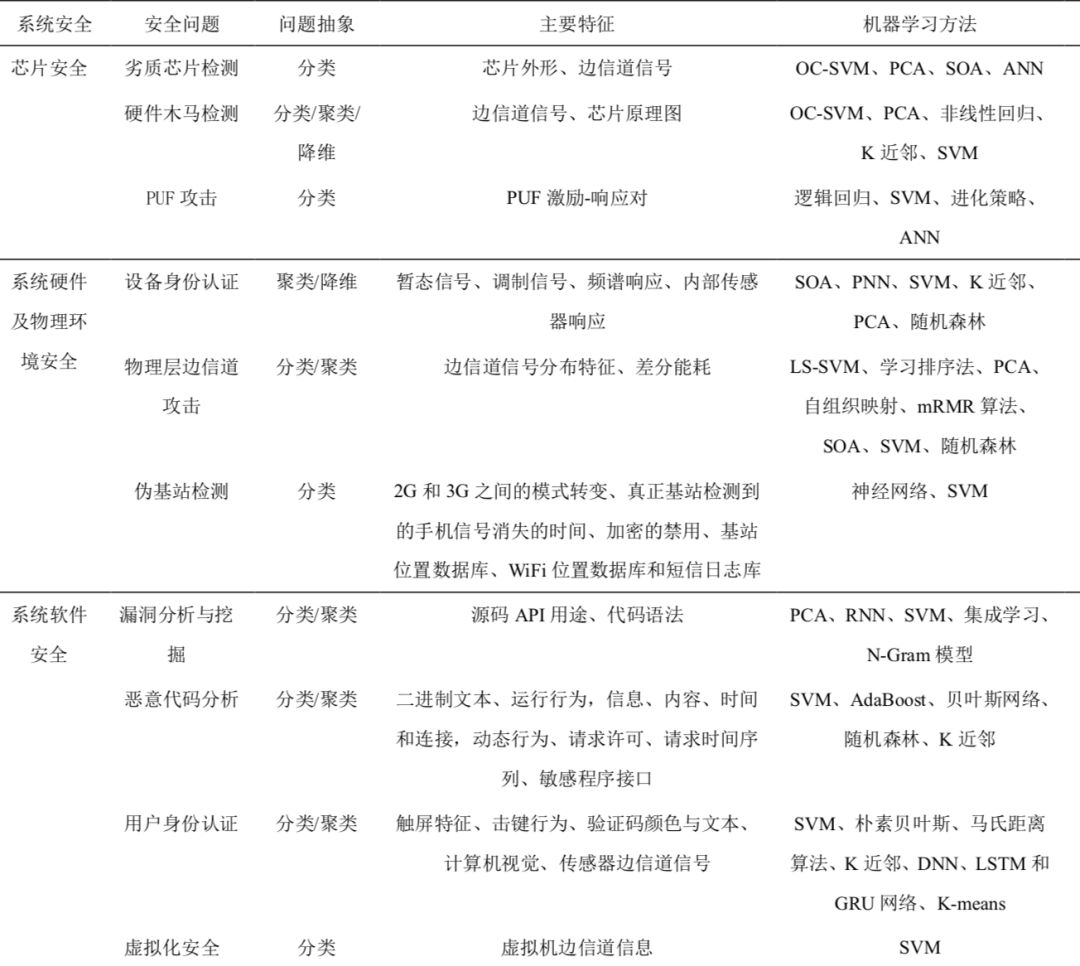
机器学习在网络安全中的应用

机器学习在应用安全中的应用

用机器学习来做安全,那是否有考虑过机器学习自身的安全性呢?这几年在软件供应链安全问题很火,就是源头安全性无法保障,同样,机器学习也面临着类似的问题
主要包括
1.平台自身缺陷,如腾讯Blade发现的针对TensorFlow的重大安全漏洞,当含有安全风险的代码被编辑进诸如面部识别或机器人学习的AI使用场景中,攻击者就可以利用该漏洞完全接管系统权限,窃取设计者的设计模型,侵犯使用者隐私,甚至对用户造成更大伤害
2. 对抗样本,对抗样本是一类被恶意设计来攻击机器学习模型的样本。它们与真实样本的区别几乎无法用肉眼分辨,但是却会导致模型进行错误的判断。对抗样本的存在会使得机器学习在安全敏感性领域的应用受到威胁

本文从安全顶会的趋势谈及机器学习在网络安全中的研究,针对机器学习的6个步骤中的典型算法给出了阐释与图示,力求通俗易懂,文中大部分总结性表格援引自《Applicationof Machine Learning in Cyberspace SecurityResearch》,在此表示真挚感谢,最后捎带提到了机器学习自身的安全问题,相信这会是现在甚至未来的一个较为热门的研究方向,笔者涉猎不深,作抛砖引玉之用。
在前文中稍微提及了机器学习的一些缺陷和挑战,因为机器学习是一种基于线性的模型,所以人类专家选择的特征只能依赖简单的线性属性。由于这种限制,一些企业及学者开始转向研究深度神经网络(DNN)。这就引出了深度学习的概念,深度学习与传统机器学习在概念上的一大区别在于,深度学习可以直接对原数据进行训练,而不需要对其特征进行抽取。具体的阐述将会在下一篇展开。
另:受限于篇幅,很多名词默认读者已经清楚不再解释,如果有不清楚的概念性问题可以文末留言,尽量及时解答。
附推荐资料:
Paper:
ieeexplore.ieee.org/document/5504793/?reload=true
https://link.springer.com/chapter/10.1007/978-3-540-30143-1_11
https://dl.acm.org/citation.cfm?id=1387709.1387716
Lecture:
https://www.youtube.com/watch?v=tukidI5vuBs
https://www.youtube.com/watch?v=vy-jpFpm1AU
https://www.youtube.com/watch?v=iLNHVwSu9EA&t=245s
https://www.youtube.com/watch?v=TYVCVzEJhhQ
https://www.youtube.com/watch?v=e5O0Oxt5dYI

