
0x01
强化学习在从0到1中已经介绍了基本的思想——从0到1:学安全的你不该懂点AI?,现在再详细介绍下。
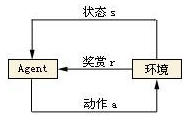
强化学习的核心逻辑,那就是智能体(Agent)可以在环境(Environment)中根据奖励(Reward)的不同来判断自己在什么状态(State)下采用什么行动(Action),从而最大限度地提高累积奖励(Reward)
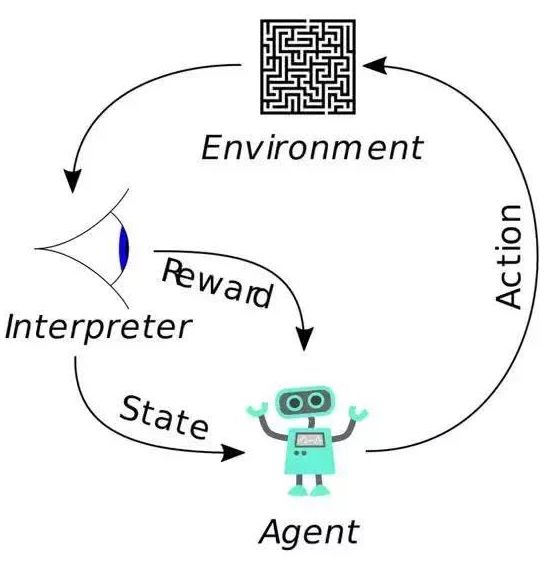
为了建立一个最优策略,Agent需要不断探索新的状态,同时最大化其所获奖励累积额度,这也被称作试探和权衡。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。
0x02
几乎所有强化学习的问题都可以转换为MDP(马尔科夫决策过程),所以有必要详细介绍下MDP。
马尔科夫决策过程是基于马尔科夫论的随机动态系统的最优决策过程。它是马尔科夫过程与确定性的动态规划相结合的产物,故又称马尔科夫型随机动态规划,属于运筹学中数学规划的一个分支。马尔科夫决策过程具有马尔可夫性,但是MDP还考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。
那么问题来了?什么是马尔科夫性?

当我们处于状态St时,下一时刻的状态St+1,可以由当前状态决定,而不需要考虑历史状态。未来独立于过去,仅仅于现在有关。(有没有回到本科概率论的感觉,顺便插个小知识点,关于接下来提到的马尔科夫过程的理论研究,1931年Α.Η.柯尔莫哥洛夫发表了《概率论的解析方法》,首先将微分方程等分析方法用于这类过程,奠定了它的理论基础。)
什么是马尔科夫过程?
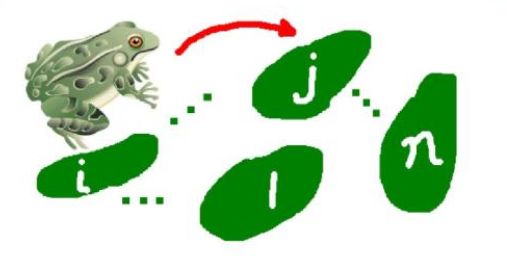
具有马尔科夫性的过程就是马尔科夫过程啦。教材里一个典型的例子就是荷花池中一只青蛙的跳跃。这是马尔可夫过程的一个形象化的例子。青蛙依照它瞬间或起的念头从一片荷叶上跳到另一片荷叶上,因为青蛙是没有记忆的,当所处的位置已知时,它下一步跳往何处和它以往走过的路径无关。如果将荷叶编号并用X0,X1,X2,…分别表示青蛙最初处的荷叶号码及第一次、第二次、……跳跃后所处的荷叶号码,那么{Xn,n≥0}就是马尔可夫过程。液体中微粒所作的布朗运动,传染病受感染的人数,原子核中一自由电子在电子层中的跳跃,人口增长过程等等都可视为马尔可夫过程。
那么马尔科夫决策过程是如何“决策”的呢?总该是类似小狗的例子中的奖励或者惩罚吧?
所以在介绍马尔科夫决策过程之前先来看一下马尔科夫奖励过程(MRP)
马尔科夫奖励过程MarkovReward Process是在马尔科夫过程的基础上增加了奖励R和衰减系数γ,其定义如下:

只要达到某个状态会获得相应奖励R,奖励描述为“当进入某个状态会获得相应的奖励”
γ是折扣因子,以下图为例
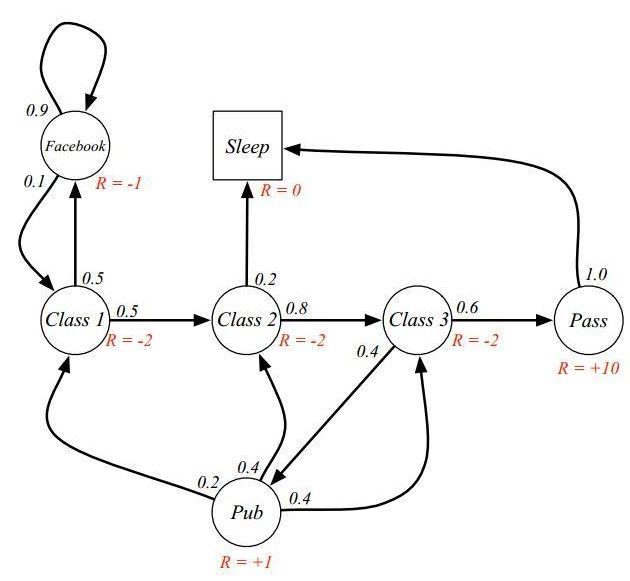
上图中的R就是奖励,是自己定义的。例如当学生处在第一节课(Class1)时,他参加第2节课(Class2)后获得的Reward是-1;同时进入到浏览facebook这个状态中获得的Reward也是-1,一般我们是说:他从class1状态离开,进入到class2状态所得到的离开立即奖励是-2,如果大家统一说法,其实就非常好理解了。由于作者认为最终目的是通过考试,所以在pass状态下离开获得的立即奖励是非常大的10。
作为Agent自然希望能够评估自己行为的长期价值,所以自然提出了价值函数
定义为:一个马尔科夫奖励过程中某一状态的价值函数为从该状态开始的马尔可夫链收获的期望
前方高能预警(在系列的文章中,我一直试图避免出现数学公式,在这儿必须得出现了,没有这几条公式,整个体系是不完整的)前面说的值函数表达式为:
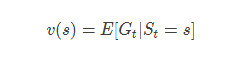
值函数的表达式可以分解成两部分:瞬时奖励Rt+1,后继状态St+1的值函数乘上一个衰减系数
如果已知转移矩阵P,则有
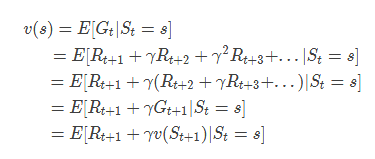
那么可以得出结论,贝尔曼等式方程就是
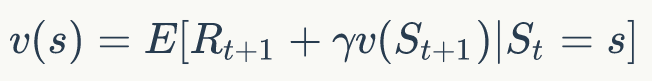
通过方程可以看出v(s)由两部分组成,一是该状态的立即奖励期望,立即奖励期望等于立即奖励;另一个是下一时刻状态的价值期望,可以根据下一时刻状态的概率分布乘以价值期望得到。

这位大佬就是贝尔曼了,一张魔鬼的面孔~

现在总结下我们已经知道的:对于某个马尔科夫过程,如果已知模型,那么就是马尔科夫链;如果引入了回报,那么就转化为马尔科夫奖励过程;如果再引入Action,就转化为了马尔科夫决策过程。
定义:一个马尔科夫决策过程由一个五元组组成<S,A,P,R,γ>
S表示状态的集合
A表示动作的集合
P描述状态转移矩阵,Pass′=P[St+1=s′|St=s,At=a]
R表示奖励函数,R(s,a)描述在状态s做动作a的奖励,R(s,a)=E[Rt+1|St=s,At=a]
γ表示衰减因子,γ∈[0,1]
马尔科夫决策过程中,多了一个决策,这个决策也就是我们前面所说的动作,在采用什么动作后,到达下一时刻的状态,并且给这个决策一个回报值来衡量该决策的好坏。
讲了这么多,还是举个例子吧。小明明天是打游戏还是学习?如果打游戏会挨打,学习会奖励小红花。挨了打会难受,得了小红花会高兴。
在这个过程中,小明相当于一个agent,有两个action,每个action的及时回报(reword)分别是挨打和小红花,选择打游戏之后状态改变为难受,选择学习后状态改变为高兴。那么长期的奖励就是选择学习则能考上大学,打游戏就考不上大学(这其实是一个持续的过程),小明要做的就是让自己获得的奖励最大化(为了考上大学,所以就得少打游戏多学习~)。
MDP的动态过程如下:智能体(agent)初始状态S0,然后从A中挑选一个动作a0执行,agent按照概率Pa随机转移到下一个状态S1,然后再执行动作a1,就转移到了S2,以此类推,可以用下图表示状态转移过程:
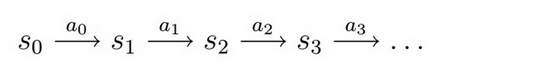
0x03
强化学习有三条线:分别是基于价值的强化学习,基于策略的强化学习和基于模型的强化学习。这三种不同类型的强化学习用深度神经网络替代了强化学习的不同部件
基于价值:Q-learning、Sarsa、DeepQ Network
基于策略:PolicyGradients
基于模型:ModelBased RL
每一种解释起来都很篇幅都很长,这里主要介绍目前已经结合网络安全有公开发表研究成果的Q-leraning,DQN和PolicyGradients
Q.Learning
Q一学习是强化学习的主要算法之一,是一种无模型的学习方法,它提供智能系统在马尔可夫环境中利用经历的动作序列选择最优动作的一种学习能力。
Q-学习基于的一个关键假设是智能体和环境的交互可看作为一个Markov决策过程(MDP),即智能体当前所处的状态和所选择的动作,决定一个固定的状态转移概率分布、下一个状态、并得到一个即时回报。Q-学习的目标是寻找一个策略可以最大化将来获得的报酬
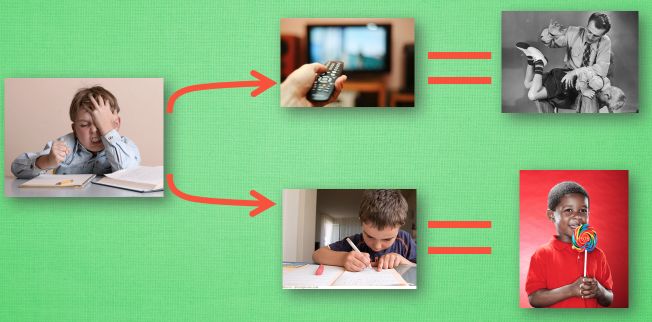
比如小时候爸妈常说”不写完作业就不准看电视”.所以我们在写作业的这种状态下,好的行为就是继续写作业,直到写完它,我们还可以得到奖励,不好的行为就是没写完就跑去看电视了,被爸妈发现,后果很严重.

假设我们的行为准则已经学习好了,现在我们处于状态s1,我在写作业,我有两个行为a1, a2, 分别是看电视和写作业,根据我的经验,在这种s1 状态下,a2 写作业带来的潜在奖励要比 a1看电视高,这里的潜在奖励我们可以用一个有关于s 和a 的Q 表格代替,在我的记忆Q表格中,Q(s1, a1)=-2 要小于Q(s1, a2)=1, 所以我们判断要选择a2 作为下一个行为.现在我们的状态更新成s2 , 我们还是有两个同样的选择,重复上面的过程,在行为准则Q表中寻找Q(s2, a1) Q(s2, a2) 的值,并比较他们的大小,选取较大的一个.接着根据a2 我们到达s3 并在此重复上面的决策过程.Q learning 的方法也就是这样决策的.
在安全领域,针对网络状态转移概率难以确定,导致无法确定求解均衡所需参数的问题,将Q-learning引入随机博弈中,使防御者在攻防对抗中通过学习得到的相关参数求解贝叶斯纳什均衡。在此基础上,可以设计能够在线学习的防御决策算法。
DQN
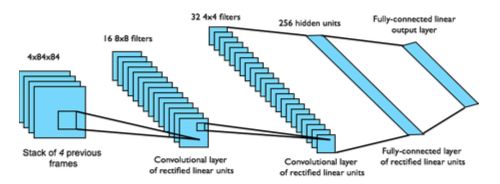
在Q-Learning中提到了Q表,它存储每一个状态state, 和在这个state 每个行为action 所拥有的Q 值. 如果全用表格来存储它们,恐怕我们的计算机有再大的内存都不够,而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事.不过,神经网络对这种事情很在行.我们可以将状态和动作当成神经网络的输入,然后经过神经网络分析后得到动作的Q 值,这样我们就没必要在Q表记录Q 值,而是直接使用神经网络生成Q 值.想象一下,神经网络接受外部的信息,相当于眼睛鼻子耳朵收集信息,然后通过大脑加工输出每种动作的值,最后通过强化学习的方式选择动作。
简单地说,就是,DQN不用Q表记录Q值,而是用神经网络来预测Q值,并通过不断更新神经网络从而学习到最优的行动路径。DQN算法的主要做法是ExperienceReplay,其将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。
在无线安全领域,厦门大学的学者指出,通过应用强化学习技术,移动设备可以实现最优的通信策略,而无需在动态游戏框架中知道干扰和干扰模型以及无线电信道模型。更具体地,提出了一种基于热启动DQN的二维移动通信方案,该方案利用类似场景中的经验来减少游戏开始时的探索时间,并应用深度卷积神经网络和宏观动作技术来加速动态情境下的学习速度。结果表明,与基准方案相比,该方案可以改善信号的信号与干扰加噪声比以及移动设备对协同干扰的效用。
在IoT物联网安全领域,以医疗为例,医疗保健起着重要作用,因为医疗信息的安全性,隐私性和可靠性是非常重要的。尽管物联网提供了维护信息的有效协议,但是一些中间攻击和入侵者试图访问健康信息,这反过来又降低了互联网环境中整个医疗保健系统的隐私性,安全性和可靠性。因此,为了解决这些问题,马来西亚理工大学的学者在研究中引入了基于学习的Deep-Q-Networks,用于在管理健康信息的同时减少恶意软件攻击。该方法根据Q学习概念检查不同层中的医学信息,这有助于以更简单的方法降低中间人攻击的风险。
PolicyGradient
我们已经知道DQN是一个基于价值value的方法。换句话说就是通过计算每一个状态动作的价值,然后选择价值最大的动作执行。这是一种间接的做法。那么,更直接的做法是什么?
能不能直接更新策略网络PolicyNetwork呢?
先说一下什么是策略网络PolicyNetwork。它就是一个神经网络,输入是状态,输出直接就是动作(不是Q值),且一般输出有两种方式:一种是概率的方式,即输出某一个动作的概率;另一种是确定性的方式,即输出具体的某一个动作。
如果要更新Policy Network策略网络,需要有一个目标函数,对于所有强化学习的任务来说,其实目标都是使所有带衰减reward的累加期望最大。如果一个动作得到的reward多,那么我们就使其出现的概率增加,如果一个动作得到的reward少,我们就使其出现的概率减小。
PolicyGradient的核心思想是更新参数时有两个考虑:如果这个回合选择某一动作,下一回合选择该动作的概率大一些,然后再看奖惩值,如果奖惩是正的,那么会放大这个动作的概率,如果奖惩是负的,就会减小该动作的概率。
PolicyGradient最简单的代码就是下图了
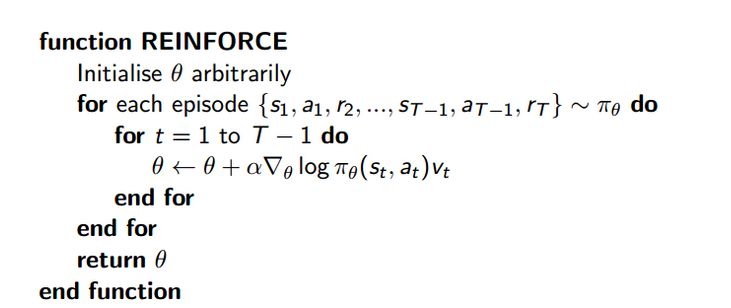
在密码学领域,所谓的物理不可克隆功能是一种新兴的新加密和安全原语。它们可以替代易受攻击的硬件系统中的二进制密钥并具有其他安全优势。慕尼黑大学的学者提出,通过使用强化学习方法来处理这种新原语的密码分析。研究了基于电路的PUF的安全性在多大程度上可以通过参数平衡的PolicyGradient的强化学习技术的挑战。研究结果表明,与其他机器学习领域和其他政策梯度方法相比,该技术在物理不可克隆功能的密码分析中具有重要优势。
0x04
强化学习到此就结束了。本系列文章也即将结束,在最后分享一下张钹院士17年在清华大学举办的“人工智能与信息安全”清华前沿论坛上的报告中关于AI+安全的一些观点和思考。
1、主题:人工智能改变信息安全的未来;信息安全促进人工智能的未来发展。
2.“入侵检测”可以带动大多数信息安全问题,入侵检测、身份认证等本质上是模式识别问题。入侵检测,要判断是入侵、非入侵;身份认证要判断是本人、非本人,可以说如果是“本人”代表不是入侵,“非本人”则代表入侵。而目前人工智能最重要的进展是在模式识别方面。
3.目前IBM最主要的是把两项技术引进Watson系统,一个是人工智能,一个是区块链技术。大家认为这是解决安全问题的两大杀手锏,第一个是区块链技术,从底层来保证数据的安全,不被篡改、不被盗窃。区块链和人工智能两个技术结合起来,有可能得到一个真正的安全系统。
4.知识驱动方法要建立很大的特征库(或知识库),但只有特征的知识是很不够的,所以基于专家系统的入侵检测的发展方向是,建立完善的知识库和推理机制,把我们对于入侵的了解变成一个知识,然后根据知识进行推理,这样就有可能去发现新的、没见过的入侵方式
5.通过强化学习自己产生数据、自己学习。人工智能的方法可以帮助我们产生数据,可以产生真实数据(正样本)、也可以产生虚假数据(负样本),这就给入侵和反入侵同时提供机会。入侵者利用这一条,产生很多假数据欺骗计算机,防守方利用同样原理产生数据(真的和假的)来训练自己,提高鉴别能力。
6.信息安全需要走人机结合这条路,不能把人完全排除在外,攻击发生在瞬息之间,几个毫秒的差错就能够引起很大的危害,特别是机器本身(包括深度学习)并不完美,很容易受到攻击,很容易受到欺骗,很容易受到干扰。在这种情况下,人怎么介入?这涉及到人工智能另外一个大家非常关心的问题,就是”人机合作“。
7.今后人工智能的发展方向,是走向可解释的人工智能。系统必须告知人类:为什么它是一个入侵,把这个道理说出来。不仅能说what,还能说why。这是我们今后的方向。机器有了自我解释的能力,才能实现人机的结合。
0x05
参考及推荐资料:
1.ReinforcementLearning: AnIntroduction(http://incompleteideas.net/book/the-book-2nd.html)
2.Algorithmsfor ReinforcementLearning(http://www.ualberta.ca/%7Eszepesva/papers/RLAlgsInMDPs.pdf)
3.RichSutton(本文部分图片引用自祖师爷的讲义)强化学习课程(http://incompleteideas.net/rlai.cs.ualberta.ca/RLAI/RLAIcourse/RLAIcourse2006.html)
4.Stanford强化学习课程(http://web.stanford.edu/class/cs234/schedule.html)
5.很接地气的国人制作的教程(部分图片引用源)https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/
文中提及的安全领域的相关研究的论文:
1.《Thedefense decision method based on incomplete information stochasticgame and Q-learning》
2《PolicyGradients for Cryptanalysis》
3.《Two-dimensionalAnti-jamming Mobile Communication Based on Reinforcement Learning》
4.《MaintainingSecurity and Privacy in Health Care System Using Learning BasedDeep-Q-Networks》

