
所有代码都已经上传到github项目上:https://github.com/smityliu/spider
大家好,最近其实一直在考虑这个项目能不能发论文,但是看起来这个项目的缺点还是很多,不足以发一篇论文或者拿去竞赛。这篇是我们项目的最后一篇,这篇的技术点相对较少,但却是整个项目的总结和整理,也让大家再次深化理解怎么做一个人物画像。
首先我们前三篇完成了这样的工作:
1.选取目标网络——2个,分别是微博和推特,选取的理由:平台类型相似,用户交集大,选取多个社交网络则是因为单一社交网络的数据偶然性和误差性大,所以必须要做多个数据的结合;
2.整个项目的步骤为:多个社交网路的数据爬取——>单个社交网络的数据分析——>多个社交网络的数据对齐——>多个社交网络的数据融合
3.多个社交网络的数据融合需要保证融合对象的一致性,因此我们在数据融合前必须要做数据对齐,利用在单个社交网络中挖掘出来的数据进行关联性分析,匹配相似度。
4.我们在单个社交网络的数据分析中,发现在微博里具有“人物准确的社会属性、大量人物日常生活语录、用户关注、用户粉丝”,在推特里具有“人物的大量日常生活语录、用户关注、用户粉丝”,但是没有个人信息,因此微博中准确的社会属性可以直接作为数据对齐后的要素,不参与数据对齐。
5.参与数据对齐的数据集合为两个社交网络的人物日常语录和,也就是我们今天要分析的主要部分
分析一下可行性
如果选取用户的粉丝来做,就会有以下问题:
粉丝数量有可能很庞大,两个网络的统一用户数据很大程度不一致
粉丝存在虚假数据
粉丝群体只能反应受众情况,不能体现具体人物的属性
如果选取用户关注来做,也会存在以下问题:
用户关注确实存在一定的相似性,但是微博是中文网络,推特是英文网络,需要做翻译
不是所有微博用户都有推特,只存在少部分同时拥有两个社交网络的用户,因此递归爬取后两个网络的数据集交集较少
如果选取用户的日常语录和博文来做,也会存在翻译的问题
综上所述,我们决定抛弃用户粉丝这块偶然性较大的数据,选取用户关注来做我们的数据对齐。
因此我们必须做一个翻译的接口调用:
访问百度API的开发平台,申请账号,在profile页面可以看到自己的APPID和密钥,记下来之后有用。

查看技术文档
通用翻译APIHTTP地址:http://api.fanyi.baidu.com/api/trans/vip/translate

请求方式:可使用GET或POST方式,如使用POST方式,Content-Type请指定为:application/x-www-form-urlencoded
字符编码:统一采用UTF-8编码格式
query长度:为保证翻译质量,请将单次请求长度控制在6000 bytes以内。(汉字约为2000个)
签名生成方法
签名是为了保证调用安全,使用MD5算法生成的一段字符串,生成的签名长度为32位,签名中的英文字符均为小写格式
Step1.将请求参数中的APPID(appid),翻译query(q, 注意为UTF-8编码),随机数(salt),以及平台分配的密钥(可在管理控制台查看)按照 appid+q+salt+密钥的顺序拼接得到字符串1。
Step2. 对字符串1做md5,得到32位小写的sign。
注:
1.待翻译文本(q)需为UTF-8编码
2. 在生成签名拼接appid+q+salt+密钥字符串时,q不需要做URLencode,在生成签名之后,发送HTTP请求之前才需要对要发送的待翻译文本字段q做URLencode

接入举例
例如:将英文单词apple翻译成中文:
请求参数:
q=apple
from=en
to=zh
appid=2015063000000001(请替换为您的appid)
salt=1435660288(随机码)
平台分配的密钥:12345678
生成签名sign:
Step1.拼接字符串1:
拼接appid=2015063000000001+q=apple+salt=1435660288+密钥=12345678得到字符串1:“2015063000000001apple143566028812345678”
Step2.计算签名:(对字符串1做md5加密)
sign=md5(2015063000000001apple143566028812345678),得到
sign=f89f9594663708c1605f3d736d01d2d4
拼接完整请求:
http://api.fanyi.baidu.com/api/trans/vip/translate?q=apple&from=en&to=zh&appid=2015063000000001&salt=1435660288&sign=f89f9594663708c1605f3d736d01d2d4
注:也可使用POST方式,如POST方式传送,Content-Type请指定为:application/x-www-form-urlencoded
之后就可以写出我们需要的翻译函数:
def translate(content, fromLang='en', toLang='zh'):
salt = str(random.randint(32768, 65536))
sign = appid + content + salt + secretKey #appid+q+salt+密钥 的MD5值
sign = hashlib.md5(sign.encode("utf-8")).hexdigest() #对sign做md5,得到32位小写的sign
#print(content)
try:
#根据技术手册中的接入方式进行设定
paramas = {
'appid': appid,
'q': content,
'from': fromLang,
'to': toLang,
'salt': salt,
'sign': sign
}
response = requests.get(apiurl, paramas)
jsonResponse = response.json() # 获得返回的结果,结果为json格式
#print(jsonResponse)
dst = str(jsonResponse["trans_result"][0]["dst"]) # 取得翻译后的文本结果
return dst
except Exception as e:
print(e)
首先余弦定理大家一定不陌生:
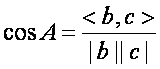
这个公式本来是用来算距离的,但是我们类比词语为一个向量,是不是就能够计算出来不同向量之间的差异,以此来代表不同坐标之间的差异性,距离越大,那么差异越大,相似度越小,如果再把文章的每一个词语表示为向量,假如文本X和文本Y对应向量分别是
x1,x2,…,x64000
y1,y2,…,y64000
其中分母表示两个向量b和c的长度,分子表示两个向量的内积。举一个具体的例子,假如文本X和文本Y对应向量分别是
![]()
当两个文本向量夹角的余弦等于1时,这两个文本完全重复;当夹角的余弦接近于一时,两条新闻相似;夹角的余弦越小,两条文本越不相关。
假设有下面两个句子:
我喜欢看电视,不喜欢看电影。
我不喜欢看电视,也不喜欢看电影。
这个时候又是应用到了我们之前的技术:分词
将每个语句用jieba分析库给他分为好多个词语
A:我1,喜欢2,看2,电视1,电影1,不1,也0。
B:我1,喜欢2,看2,电视1,电影1,不2,也1。
并将其变为词向量,其实也很简单,大家可以对照词向量来重新组合一下词语,会发现就是我们那两个句子
A:[1,2, 2, 1, 1, 1, 0]
B:[1,2, 2, 1, 1, 2, 1]
不过对于我们的文本来说,其实我们就是在验证用户关注构成的词语,他们已经就是一个个人名了,即使把他们翻译过来,他们还是个人名,所以我们只需要做词向量那步就可以了
然后就是我们的计算距离了,将翻译函数带入我们的脚本,翻译后带入到我们的余弦定理公式
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import division
import jieba.analyse
from math import sqrt
from functools import reduce
import hashlib
import random
import openpyxl
from openpyxl import Workbook
import requests
apiurl = 'http://api.fanyi.baidu.com/api/trans/vip/translate'
appid = '20191231000371318'
secretKey = 'wMXgSdRsUI_XmGtf8JC2'
class Similarity():
def __init__(self, target1, target2, topK=10):
self.target1 = target1
self.target2 = target2
self.topK = topK
def vector(self):
self.vdict1 = {}
self.vdict2 = {}
top_keywords1 = jieba.analyse.extract_tags(self.target1, topK=self.topK, withWeight=True)
top_keywords2 = jieba.analyse.extract_tags(self.target2, topK=self.topK, withWeight=True)
for k, v in top_keywords1:
self.vdict1[k] = v
for k, v in top_keywords2:
self.vdict2[k] = v
def mix(self):
for key in self.vdict1:
self.vdict2[key] = self.vdict2.get(key, 0)
for key in self.vdict2:
self.vdict1[key] = self.vdict1.get(key, 0)
def mapminmax(vdict):
"""计算相对词频"""
_min = min(vdict.values())
_max = max(vdict.values())
_mid = _max - _min
#print _min, _max, _mid
for key in vdict:
vdict[key] = (vdict[key] - _min)/_mid
return vdict
self.vdict1 = mapminmax(self.vdict1)
self.vdict2 = mapminmax(self.vdict2)
def similar(self):
self.vector()
self.mix()
sum = 0
for key in self.vdict1:
sum += self.vdict1[key] * self.vdict2[key]
A = sqrt(reduce(lambda x,y: x+y, map(lambda x: x*x, self.vdict1.values())))
B = sqrt(reduce(lambda x,y: x+y, map(lambda x: x*x, self.vdict2.values())))
return sum/(A*B)
def translate(content, fromLang='en', toLang='zh'):
salt = str(random.randint(32768, 65536))
sign = appid + content + salt + secretKey #appid+q+salt+密钥 的MD5值
sign = hashlib.md5(sign.encode("utf-8")).hexdigest() #对sign做md5,得到32位小写的sign
#print(content)
try:
#根据技术手册中的接入方式进行设定
paramas = {
'appid': appid,
'q': content,
'from': fromLang,
'to': toLang,
'salt': salt,
'sign': sign
}
response = requests.get(apiurl, paramas)
jsonResponse = response.json() # 获得返回的结果,结果为json格式
#print(jsonResponse)
dst = str(jsonResponse["trans_result"][0]["dst"]) # 取得翻译后的文本结果
return dst
except Exception as e:
print(e)
def confir(str):
for i in range(0,32):
str = str.replace(chr(i),'')
for i in range(1000,200000):
str = str.replace(chr(i),'')
return str
if __name__ == '__main__':
with open('weibo/孙燕姿.txt','r',encoding='utf-8') as f:
t1 = f.read().replace('[','').replace(']','').replace('\'','')
#t1=t1.split(',')
#print(list(t1))
with open('twitter/Stefsunyanzi.txt','r',encoding='utf-8') as f:
t2 = f.read().replace('[','').replace(']','').replace('\'','')
t2=confir(t2)
t2=translate(t2)
print(t2)
#t2=t2.split(',')
#print(list(t2))
topK = 100
s = Similarity(t1, t2, topK)
print(s.similar())
最后计算出来我们的结果如下:

其实这里会有很多的问题:
1.不是所有明星都有微博和推特
2.相似度大于0的就没有多少,而且数值很低
但是我们最后还是能找到几个按照数值判断能合在一起的,比如:科比,孙燕姿,甄子丹,乔丹
我们把最后孙燕姿的微博和推特融合起来看看结果:

出现了比较多的相关词语比如“演唱会”、“stesunyanzi”这些,说明融合后兴趣属性描述的更加准确了。
好了我们的人物兴趣属性分析到这里就全部结束了,我主要还是讲一下我的缺点,因为后来找了专业的机器学习大佬交流,他们给了比较多的意见:
1.推特和微博在现在的社交数据大赛上有着现成的数据集,可以直接使用,不要自己爬取
2.不要使用lda,建议使用神经网络模型
3.数据集种子选取的没有道理,无法证明能够覆盖某一范围
4.爬虫确实工作量比较大,机器学习的成分太少
如果有同学还想继续往下深入,不妨可以找我一起讨论。
合天网安实验室推荐 : Python爬虫简单实践
http://www.hetianlab.com/cour.do?w=1&c=CCID6b56-479f-4de1-a001-b8530dd99125
(课程包括了简单的内网服务器爬取,还用实际案例合天网安实验室和百度给大家进行演示,快来开启你的爬虫学习之旅吧!)

