
前一段时间一直想解决一下字符编码问题,从而研究了Python
(Python2.7版本)、PHP、MYSQL等在字符编码方面的原理,从根本上理解编码问题产生的根源,以及一些有效的解决办法。本文打算从两大部分出发分别介绍各个语言在编码上的处理机制,以及由编码问题造成的漏洞。
总的来说字符编码问题可以归结为以下几点
以错误的方式解析字符编码
在编码转化时被转化的编码没有相应的值
在编码转化时没有相应的值与被转化的编码对应
简单介绍几种方式
UTF-8
UTF-8是一种变长字节编码方式。对于某一个字符的UTF-8编码,如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
GBK
专门为解决汉字的编码而生成的解决方案
GBK的中文编码是双字节来表示的,英文用单字节表示,但GBK编码表中也有英文字符的双字节表示形式,所以英文字母可以有2种GBK表示方式。为区分中文,将其最高位都定成1。英文单字节最高位都为0。
0x1 Python
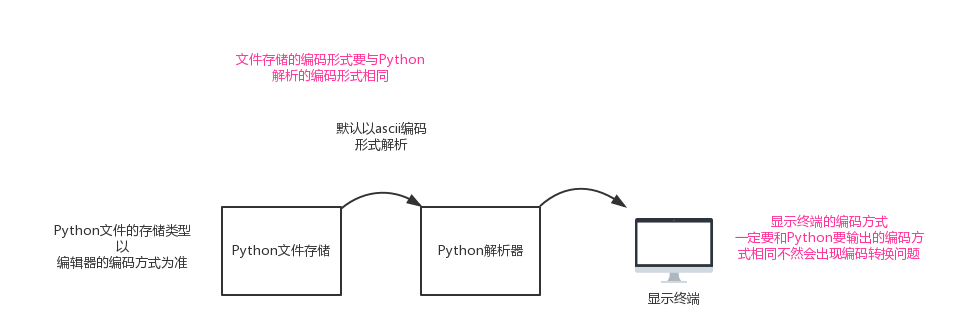
整体分为三大部分,从存储、解析到显示。
python里string object和unicode
object是两种不同的类型,string里的character是有多种编码方式的,比如单字节的ASCII,双字节的GB2312等等,再比如UTF-8。很明显要想解读string,必需知道string里的character是用哪种编码方式,然后才能进行。
Python解析器从文本中解析代码,需要知道文档的编码方式一般在文档开头
# coding:utf-8 # -*- coding:utf-8 -*-
例如:
# encoding:utf-8 print "한"
此时文档应当按照utf-8编码存储,因为Python 解析器会以utf-8的格式读取存储在磁盘上的二进制,如果存储格式有误就会出现解析错误。例如下面报错信息
SyntaxError: Non-ASCII character '\xe5' in file F:\code\python\2.py on line 4, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Python 解析器默认以ascii进行解析,'\xe5'超出ascii编码范围,因此解析错误。
另一种改变python 解析器的默认解析编码为使用UTF-8-BOM进行存储。


不用使用头部注释即可解析中文字符编码,利用hexdump工具可以看出其中的文件头有三个标志字符ef bb bf
至此Python加载文件的编码操作已经结束,下面就是在Python解析器中的操作,可以说是在内存中的操作。
由前面的介绍可以了解到Python中的字符类型分为string 和 unicode,其中string 又包括了gbk、utf-8等各种编码。他们之间的转化通过encode和decode进行
>>> a = '啊'
>>> a '\xb0\xa1'
>>> a.decode('gbk') u'\u554a'
>>> a.decode('gbk').encode('utf-8') '\xe5\x95\x8a' 因为终端使用的是gbk编码,所以 啊的编码为'\xb0\xa1' 以gbk编码格式进行解析,解析成unicode编码,再使用encode编码方式编码成utf-8。
在这里需要再次强调一下Python string的默认编码方式 ascii形式,也就是说在不指定string编码方式的情况下默认以ascii进行解析,因此会造成很多编码问题。
比如下面两个例子,正好将encode和decode函数都有讲解到
Python 写入字符串到文件
这里只针对py2,
write方法的参数类型是str,str是二进制流(不包含编码信息),当给出一个unicode对象时,会执行str函数转换成str类型再送给write方法。unicode转str包含一次编码,如不指定则默认使用ascii编
看下面的错误
# coding:utf-8
a = u'啊'
f = open('./111','a')
f.write(a) Traceback (most recent call last): File "F:\code\python\2.py", line 4, in <module> f.write(a) UnicodeEncodeError: 'ascii' codec can't encode character u'\u554a' in position 0: ordinal not in range(128)
这里产生错误的原因是,unicode首先要encode转化为ascii编码,显然有很多字节是对不上号的,这里的解决方法有两个,其一是改变其默认编码使用下面代码
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
a = u'啊'
f = open('./111','a')
f.write(a) 其二将unicode转换为其他编码过后再次存入文件
# coding:utf-8
a = u'啊'
f = open('./111','a')
f.write(a.encode('gbk')) 绕过unicode直接进行编码转化
首先看下下面代码
>>> a = '啊'
>>> print a.encode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xb0 in position 0: ordinal not in range(128) a原本为gbk编码,如果直接进行encode那么首先会转换编码为unicode格式,因为默认解析格式为ascii所以在ascii转换成unicode编码时会产生以上错误。那么这时可以改变默认编码
# coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
a = '啊'
print a.encode('utf-8') 成功解决该类编码问题
在第二小节的图示中最后一个环节,是终端编码的问题。
问题一般出在交给操作系统的字符编码与终端显示编码有所差别。
在windows cmd终端采用的gbk编码
如果使用utf-8编码就会出现乱码

在linux 终端下采用的是utf-8编码形式
如果使用gbk编码就会出现乱码

PHP编码相对 Python而言简单了许多,PHP直接使用ascii进行单字节解析,也就是说不论文件采用什么编码,PHP在解析是总是按字节处理,如下面例子:
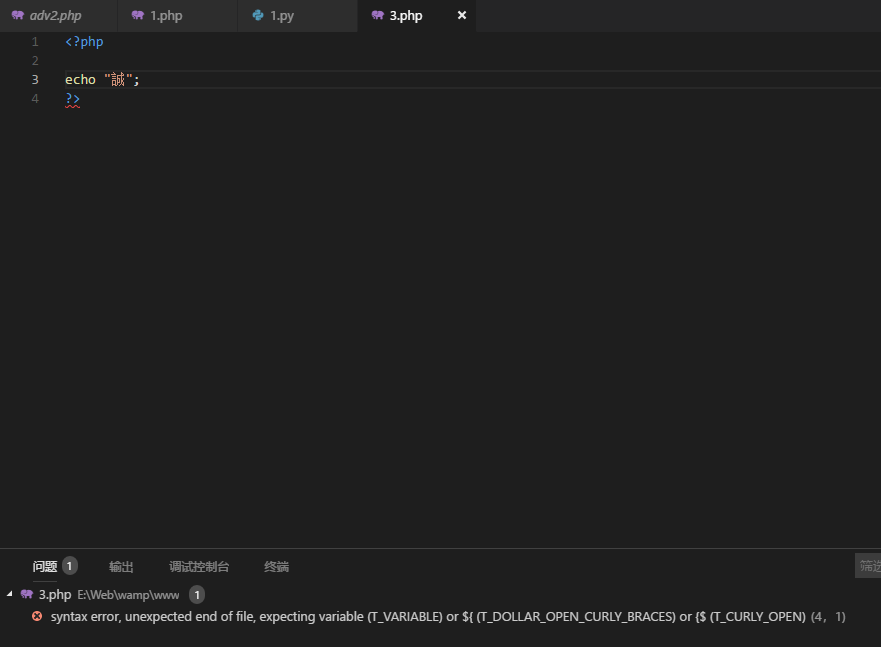
该PHP脚本采用gbk编码方式编码,"誠" 字的字节码为"D55c" 5c为\使得PHP解析错误。
PHP以及HTML脚本可以指定显示在浏览器上的编码方式
header("content-type:text/html;charset=utf-8") <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
mysql 编码数据比较复杂,大体上可以分为以下几个
character_set_client
无论客户端传递的是什么编码的数据,服务器都当成该编码来处理,例如该编码为UTF8,那么如果客户端发送过来的数据不是UTF8,那么就会出现乱码;
character_set_connection
connection 可以说是在SQL语句执行时的编码 ,当执行的是查询语句时,客户端发送过来的数据会先转换成connection指定的编码。但只要客户端发送过来的数据与client指定的编码一致,那么转换就不会出现问题;
数据字段存储
当insert数据时需要将数据存储在数据库中,这里就涉及到编码转化,当没用找到对应关系时就会令该位置字符为3F ,这也是数据库中乱码中3F出现的原因。
character_set_results
当select从数据库中取出时以前的编码要变为character_set_results设置的编码。
整个流程可参照下图:
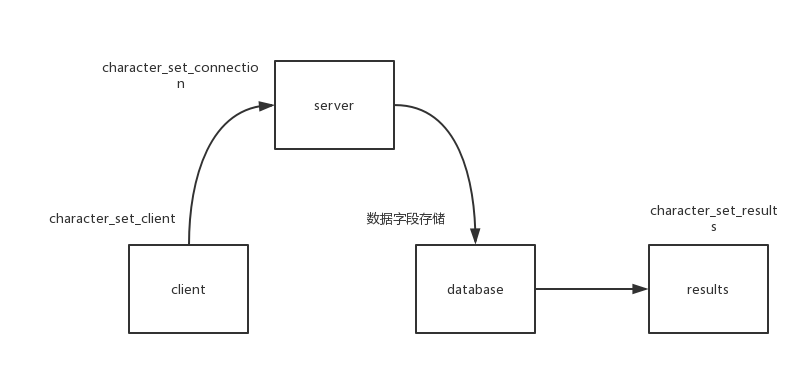
从查询到取出整个流程经历了三次编码转换,每次转换都有可能产生编码问题。client编码指定了用户输入的编码格式,connection按照此编码格式将编码转化为connection指定的编码,然后再将编码转化为存储格式。当有查询操作时再将取出的数据按照results格式转化。这里盗用一张图
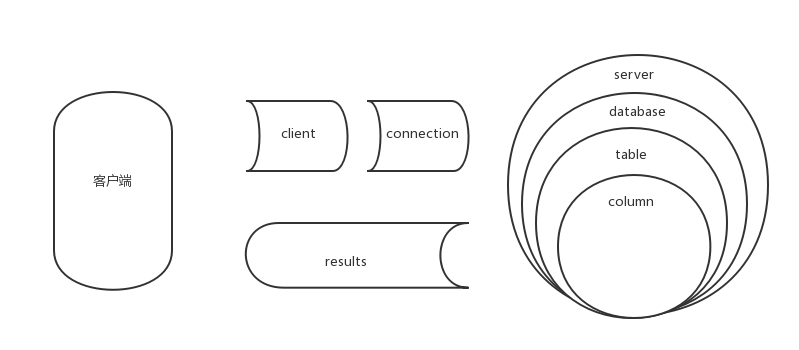
设计以下实验
实验一 (验证数据存储时的转换)
写一个数据库交互的代码,在前端使用GBK编码方式插入数据,character_set_client设置为GBK,character_set_connection设置为GBK,数据存储设置为utf8,查看最后的存储字节为E8AAA0为正确的utf8编码
http://127.0.0.1/1.php?a=%d5%5c
$conn->query("SET character_set_client = gbk");
$conn->query("SET character_set_connection = gbk");
ALTER TABLE `yz` CHANGE `a` `a` TEXT CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL; 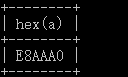
实验二(验证client到connection的转换)
在前端使用GBK编码方式插入数据,character_set_client设置为GBK,character_set_connection设置为utf8,数据存储设置为utf8,查看最后的存储字节为E8AAA0为正确的uft8编码
http://127.0.0.1/1.php?a=%d5%5c
$conn->query("SET character_set_client = gbk");
$conn->query("SET character_set_connection = utf8");
ALTER TABLE `yz` CHANGE `a` `a` TEXT CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL;
实验三(验证数据存储到取出的显示的转换)
将以utf8编码存储的内容用gbk格式取出
http://127.0.0.1/1.php?a=%d5%5c
$conn->query("SET character_set_client = gbk");
$conn->query("SET character_set_connection = utf8");
$conn->query("SET character_set_results = gbk");
ALTER TABLE `yz` CHANGE `a` `a` TEXT CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL; 成功转化为gbk格式,没有乱码出现enter code here

让我们回顾一下GBK宽字节注入的相关细节
在可以使用单引号的前提下,使用addslashes将单引号转义,又因为database使用的是GBK编码,所以如果前面有%d5等字节存在,就会将反斜杠吃掉变为%d5%5c在gbk编码里面这是一个合法字符所以只剩下单引号,成功逃逸。
在研究编码问题的时候发现PHP是按照字节处理的所以如果对于%d5%5c这样的gbk编码如果使用addslashes的话会变成%d5%5c%5c,这样在SQL
server处理的时候如果以gbk格式进行数据查询就会 多出一个反斜杠 ,利用该反斜杠可以转移其他特殊字符,具体使用方法如下:
源码链接
$conn->query("SET NAMES 'gbk'");
sql_get("select * from yz where b='$a' and c='$b'"); 如果$a和$b两个参数分别传入
a=%d5%5c&b=or 1 %23
经过编码解析成为
select * from yz where b='誠\' and c='or 1 #'
成功进行注入
系统的总结了在以前学习过程中遇到的编码问题,学习了编码问题产生的原因以及纠错方法,同时在研究过程中找到了新的漏洞所在。那么总结来看编码问题还是三大点
以错误的方式解析字符编码
在编码转化时被转化的编码没有相应的值
在编码转化时没有相应的值与被转化的编码对应
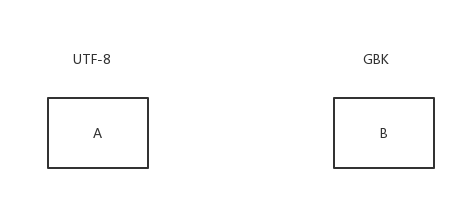
上图中A是UTF8编码,B是GBK编码,简单来讲上述问题可以这么描述
A字符串用GBK编码进行解析,必然会产生编码错误
现在A要转化为B种编码,但在解析A时默认编码为ascii,从而出现解析错误
现在A要转化为B种编码,以UTF-8格式解析A,但在转化成GBK编码时发现没有对应的字符编码,这里就出现了转换错误
简单的总结到这里,如果后面遇到了其他问题会及时补充,如果描述有错请及时指正。
文章仅用于普及网络安全知识,提高小伙伴的安全意识的同时介绍常见漏洞的特征等,若读者因此做出危害网络安全的行为后果自负,与合天智汇以及原作者无关,特此声明。

