
#前言
这是IoT的时代,这也是AI的时代。
在IoT时代,针对IoT设备上的密码芯片进行侧信道分析是极其活跃的领域,是研究IoT安全至关重要的一环。在AI时代,目前引领AI第三次复兴的技术便是深度学习。将侧信道与深度学习相结合会有什么效果,本文对此进行了尝试。
侧信道分析部分,思路是根据power trace(能耗轨迹),从运行在ARM CPU上的AES算法实现中恢复AES密钥。在深度学习则是赋能于侧信道分析,我们将power trace处理后的数据集作为深度学习系统的输入,训练神经网络,使其预测key字节,作为输出。
下文中我们会首先介绍AES、侧信道分析、深度学习等前置知识,然后以实战为导向实现对16字节密钥的恢复。
#AES
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。经过五年的甄选流程,高级加密标准由美国国家标准与技术研究院(NIST)于2001年11月26日发布于FIPS PUB 197,并在2002年5月26日成为有效的标准。现在,高级加密标准已然成为对称密钥加密中最流行的算法之一。
AES的区块长度固定为128比特,密钥长度则可以是128,192或256比特;而Rijndael使用的密钥和区块长度均可以是128,192或256比特.(本文就是针对密钥长度为128比特(16字节)的AES实现进行攻击)。
大多数AES计算是在一个特别的有限域完成的。
AES加密过程是在一个4×4的字节矩阵上运作,这个矩阵又称为“体(state)”,其初值就是一个明文区块(矩阵中一个元素大小就是明文区块中的一个Byte)。(Rijndael加密法因支持更大的区块,其矩阵的“列数(Row number)”可视情况增加)加密时,各轮AES加密循环(除最后一轮外)均包含4个步骤:
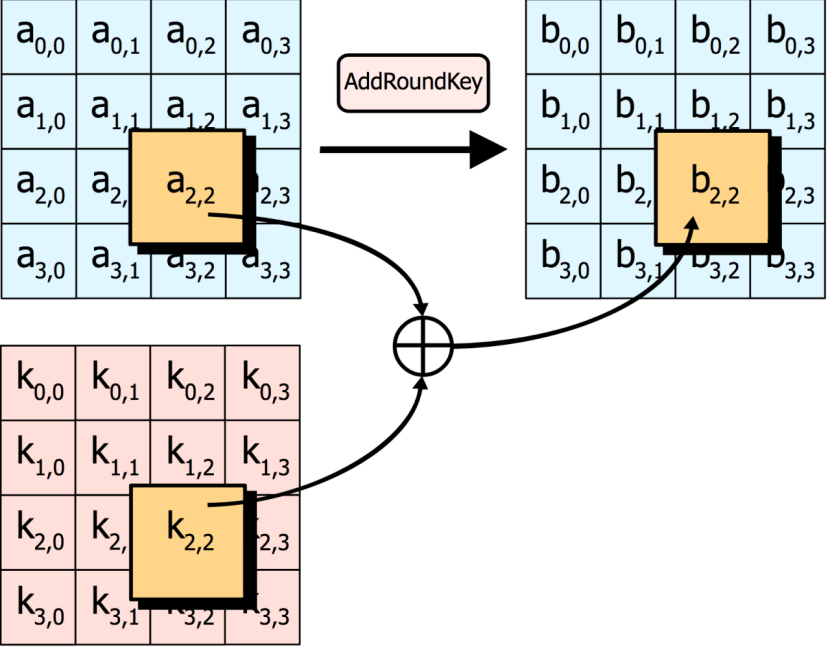
AddRoundKey—矩阵中的每一个字节都与该次回合密钥(round key)做XOR运算;每个子密钥由密钥生成方案产生。
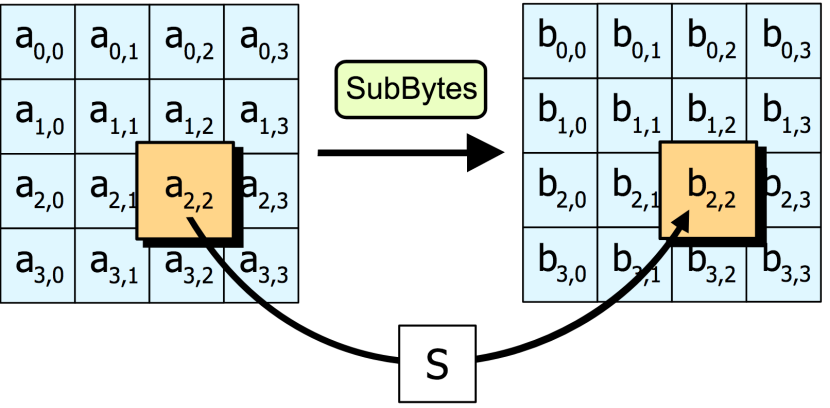
SubBytes—透过一个非线性的替换函数,用查找表的方式把每个字节替换成对应的字节。
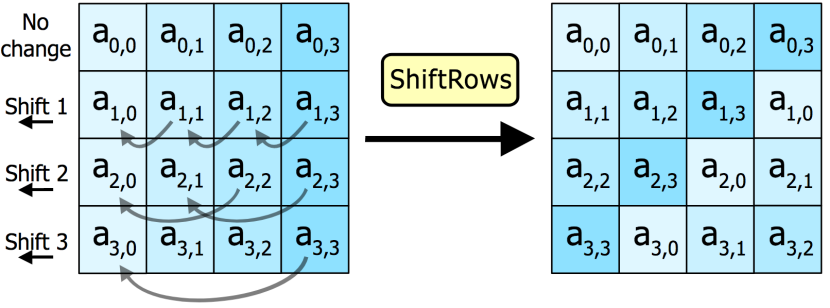
ShiftRows—将矩阵中的每个横列进行循环式移位。
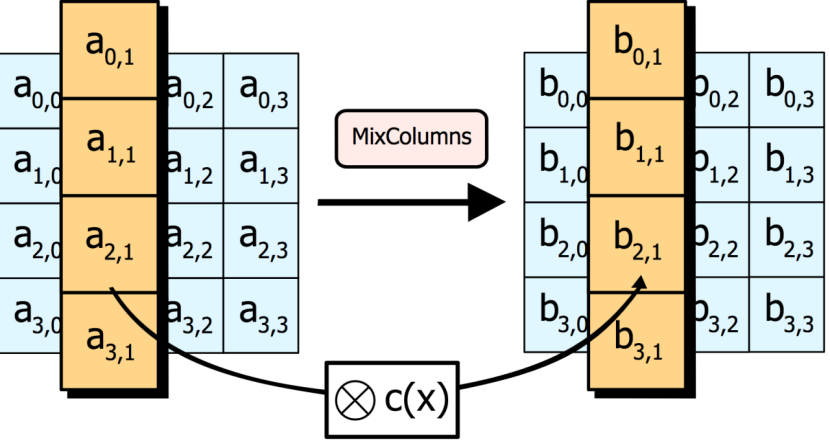
MixColumns—为了充分混合矩阵中各个直行的操作。这个步骤使用线性转换来混合每内联的四个字节。最后一个加密循环中省略MixColumns步骤,而以另一个AddRoundKey取代。
#侧信道攻击
侧信道攻击的过程可以简单概括为:攻击者使用示波器采集密码算法在目标设备上运行时的计时、功耗、电磁辐射、声音、热量、射频、故障输出等旁路泄露信息,接着分析这些信息和密码设备执行过程中的中间运算、中间状态的关系(这些中间运算、中间状态依赖于密码算法的密钥),进而根据分析结果恢复出密钥。攻击者采集的旁路泄露信息又被称作能量轨迹(power trace),在分析power trace和中间运算、中间状态的关系之前,需要对power trace进行预处理(见下文)。
另外,在下文会提到“攻击点”的概念,这里先做说明。
攻击的目标是恢复key字节的值,但是在实际中除非你捕获到了加载到内存中的key,否则而基本不会直接捕获到key。事实上,我们预测的是称为攻击点的值,这些攻击点也叫做敏感变量。攻击点是内存中的点,在这个点上,计算会导致内存出现变化(比如更改了一个寄存器的值,或者设置了值等),这些变化与我们尝试恢复的key有关系(比如异或)。更改内存值会导致功耗发生变化,这意味着这些更改可以从功耗轨迹中发现。
如下图所示
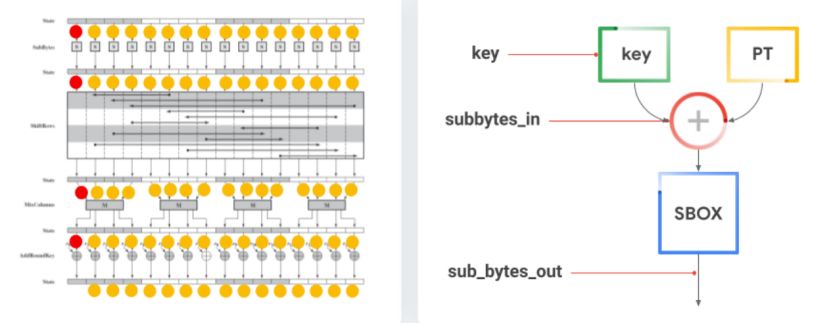
左图是AES中所有的攻击点(攻击点由黄/红点表示),然而在实际应用上,他们大多数是不可逆的,可逆的意思是说可以从猜测值推测出key字节的值。只有红点是直接可逆的,他们都位于第一轮,示意图如上图的右图所示。
可以看到组成包括key、sub_bytes_in,sub_bytes_out。
其中key是我们希望通过推理得到的,sub_bytes_in是当key和明文一起存储后的目标字节的值,sub_bytes_out是使用AES盒替换另一个值之后的字节值。
对于我们要攻击的算法来说,sub_bytes_in,sub_bytes_out都很容易受到攻击。
#深度学习
深度学习(英语:deep learning)是机器学习的分支,是一种以人工神经网络为架构,对资料进行表征学习的算法。
深度学习是机器学习中一种基于对数据进行表征学习的算法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征
为什么使用深度学习来做SCA?
第一点最显然的原因,也是其他领域也会使用深度学习的原因,就是深度学习可以直接从原始功耗或trace中学习,而不是依赖人工设计的特征和假设,这使得攻击更易设计,减少了对特定领域专业知识的需求。第二点是因为模型可以直接学习预测目标中间值,而不需要使用近似模型(相当于模板攻击而言),这也简化了攻击设计。第三点是因为使用深度学习可以进行概率攻击(利用softmax),因为模型在多个power trace上输出的分数可以被直接排序得到可能性最大的字节值。
#构建数据集
首先我们需要构建数据集,之后才能在其上训练模型。这一步的关键就是收集power trace
怎么收集power trace呢?
流程如下所示
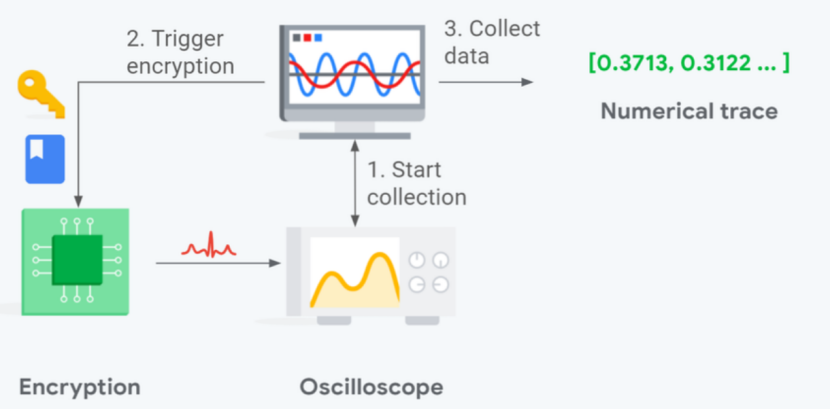
1.启动示波器开始捕获
2.触发硬件上的加密过程(选定的或者是随机的key和明文进行加密)
3.在加密结束时,停止捕获并从示波器收集power trace。我们构造数据集时会将trace及对应的标签(使用的key和明文)都加入进去
我们使用示波器来捕获,所需的硬件设备示意图如下所示

红板中间放的是待分析的芯片,下面是示波器的probe,两端分别连接到通信接口和芯片,示波器的捕获的什么样子呢?
在示波器每次捕获之后,可以得到一组与下图类似的power trace
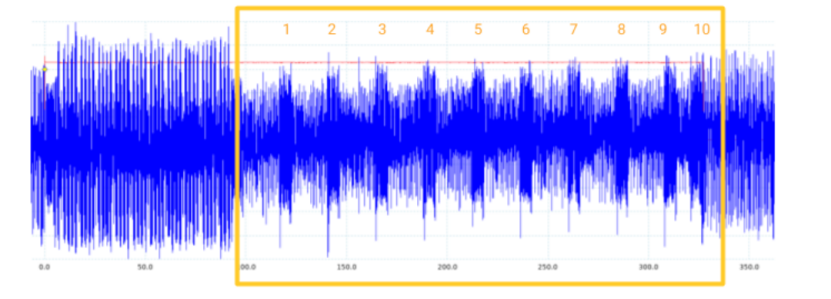
上图显示了没有受到保护的AES实际实现时的power trace,这种情况下很容易就可以进行SCA,因为我们可以清楚地看到10轮AES(上图已经标注出来了)
然后需要将power trace转为深度学习可用的数据集,这里涉及到3个操作:
1.数据处理。我们将power trace缩放到[-1,1],如果不这么做,大多数模型是不会收敛的
2.计算攻击点。对于每条轨迹,我们预先计算期望的_sub_bytesin 和_sub_bytesout 值。然后执行矩阵转置,以确保数据的格式是[ byte _ id ][ example _ id],因为我们希望能在对密钥的单字节攻击时可以通过byte_id获取数值。然后还需要对每个字节值进行分类编码(categorical encoding),因为模型的输出是256个潜在值上的softmax。
3.将数据打包成分片(shard)。分片中包含给定key value的所有样本。这可以让我们调整每个key需要多少样本,并确保在训练和测试时使用不同的key。
数据集有了之后我们就可以开始训练了
#训练模型
训练的目的是为了使用先前收集的trace建立模型。传统的SCA都会使用模板攻击等方式学习这些模式。模板攻击是使用训练数据执行多元统计分析,创建一个被称为汉明加权模型(Hamming Weight Power Model)的近似泄露模型(leakage model)。模板攻击可以类比于CV领域中旧的视觉算法,依赖于人类精心设计的特征,而使用深度学习模型可以直接从原始数据中学习。
在训练模型之前,需要加载数据集

还要加载配置文件

配置文件内容如下
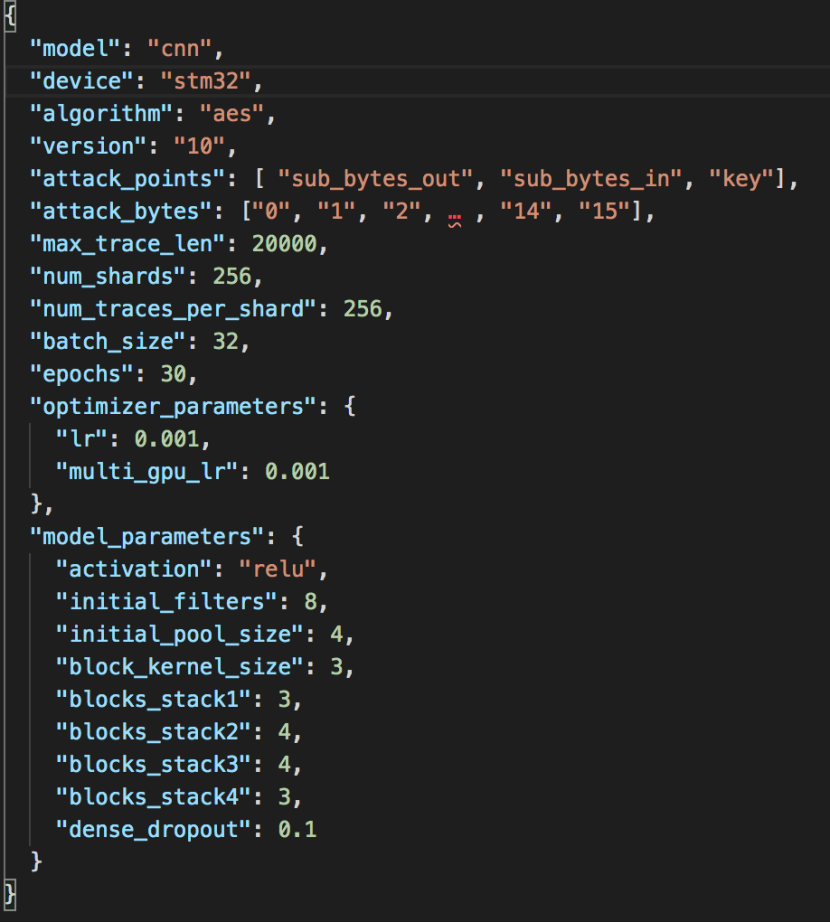
其中主要用于设置四项内容:
1.攻击目标。从device和algorithm看到,指定了要攻击的设备以及其上运行的算法。
2.攻击方式。从attack_points和attack_bytes可以看到.前文我们已经提到,AES 128的16字节密钥有3个攻击点,所以实际我们需要训练3*16=48个模型
3.攻击所需数据。从num_shards,num_traces_per_shard可以看到,一个shard包含给定的key的所有样本,因此shard的数量等于要使用的key的数量。num_traces_per_shard指的是给定的key使用多少不同的power trace。
4.攻击所需架构。包含模型的参数、优化器等。
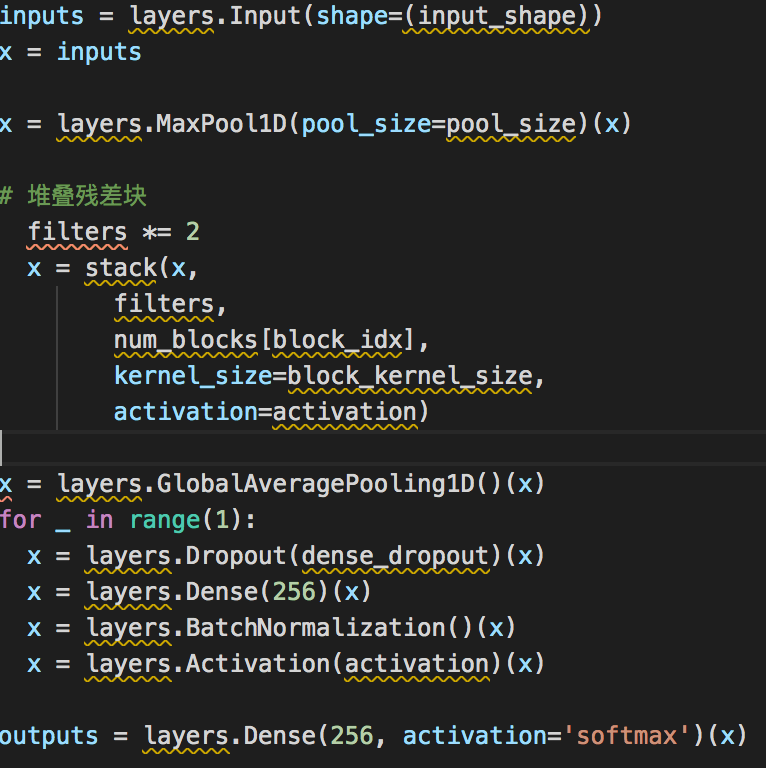
本文使用的是带残差的CNN,即ResNet,但是有一些不同
1.由于我们处理的是时间序列,shape为(batch_size,trace_len,value),而不是图像(shape为(batch_size,width,height,channels)),所以使用的一维卷积
2.模型一开始用的是max pooling,这是因为之前采样的时候是过采样的,使用max pooling可以使模型更小,以便更快地收敛
3.使用了卷积增长函数的简化的stack(堆),其实每个stack就是将过滤器数量翻倍
dropout用于帮助泛化,之后是全连接层、激活层和BatchNormalization层,输出层是带有softmax激活的256输出的全连接层
网络的一般结构如下
残差块结构如下
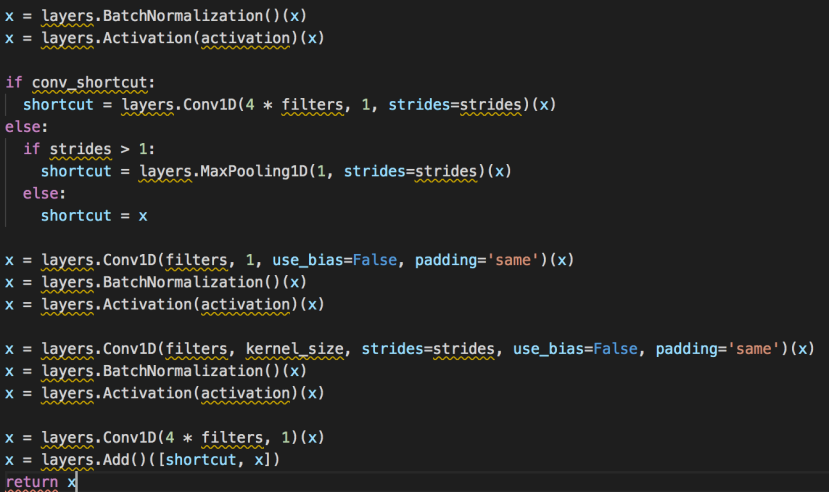
从批归一化开始,在进行卷积之前通过激活层。正如前面提到的,我们这里用的是一维卷积,即Conv1D;其他的都和标准残差架构一样,不再另做说明。
模型搭建完成后,使用训练集进行训练即可。
#攻击
这一步,我们利用训练好的模型来恢复训练过程中没见过的key。
我们将深度学习应用于侧信道攻击的优势就是它可以根据trace数量可扩展地进行概率攻击,我们只需要累计模型的预测值就可以了,如下所示,累计的结果越大,则该值越有可能是对应字节的值。
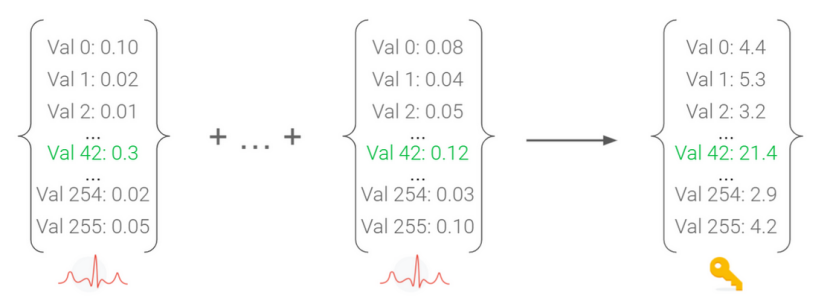
为什么这么直接加起来就可以来了?因为我们之前在输出层用的是softmax,softmax就是用于将模型的输出转为概率分布,他们的和等于1,如下所示
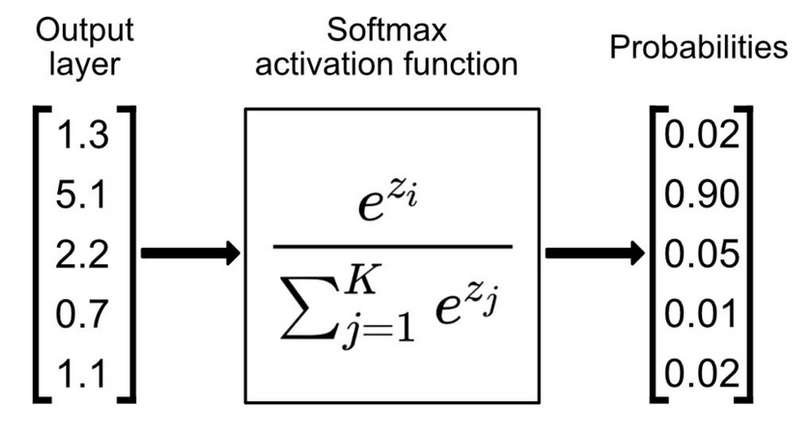
现在还有一个问题,怎么评估侧信道攻击的效果呢(除了直接看是否恢复出了给定的key)
在本文中主要评估恢复给定key需要多少条trace,评估指标可以是:恢复key所需的最少trace是几条?平均需要几条trace才能恢复key?恢复所有key需要多少trace?以及通过攻击曲线(如下所示)来看累计成功率,我们以恢复16字节的key中的一个字节为例来看看。

我们画出攻击中的密钥恢复效率,实际就是打印攻击曲线
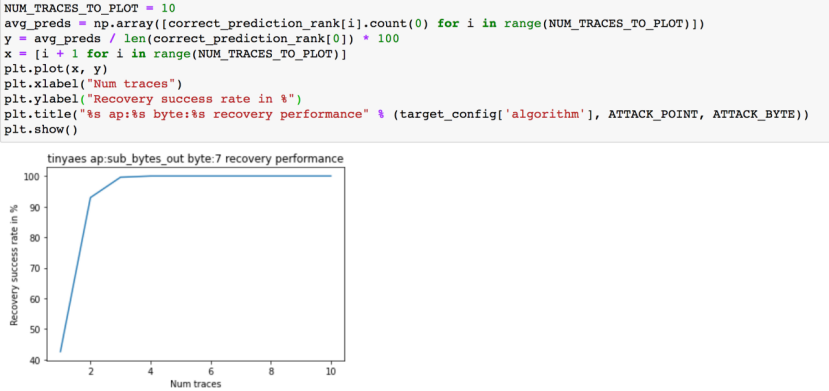
下面给出的累计成功率就是上图曲线下的面积。如果是完美的攻击,其曲线下面积应为1,这说明1个trace就可以恢复出全部的key,但是这基本不会发生,我们要做的是找到曲线最陡或者说曲线下面积最大的攻击,因为这种攻击的性能最好。
下面的代码用于计算并打印指标
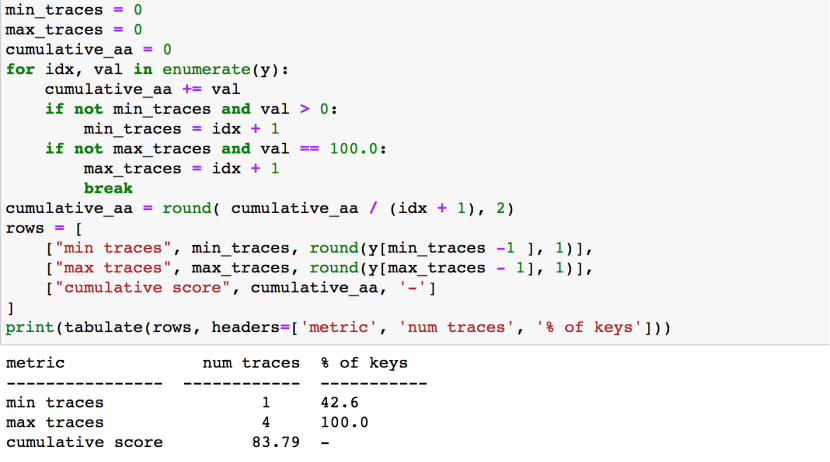
从上图结果可以看到,使用1个trace可以恢复40%左右的key,为了恢复全部key,需要4个trace,累计成功率为83.79%
现在我们尝试恢复出AES的完整的key。
攻击前,还需要设置参数:攻击点可以设为sub_bytes_out;从攻击曲线的图中可以看到其实不需要10条trace,5条trace就足够了;此外还需要设置目标shard,一个shard就是一个不同的key,随意设置即可

我们运行16次字节恢复算法,一次可以恢复出一个key字节
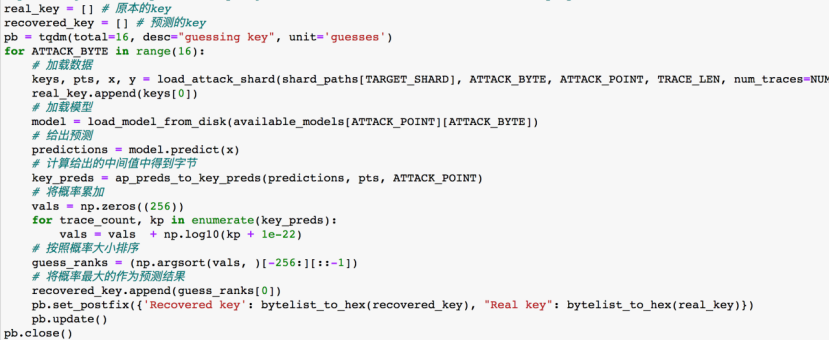
运行得到的结果如下

可以看到基本预测正确。
#参考
2.https://zh.wikipedia.org/wiki/%E9%AB%98%E7%BA%A7%E5%8A%A0%E5%AF%86%E6%A0%87%E5%87%86
4.https://zh.wikipedia.org/zh-hans/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0
5.https://www.youtube.com/watch?v=Db8mj5KFz8E
6.https://docs.google.com/presentation/d/1l-TpGGuGu40TS4ecqPfzLqrzSQccwgu3BlsKMTyZbSk/edit

